本文参考课程大数据可视化
[TOC]
可视化的研究内容
科学可视化
研究带有空间信息和几何信息的三维测量数据,如计算模拟数据、医学影像数据的可视化。其核心挑战是挖掘数据中几何、拓扑和形状特征。
信息可视化
研究非结构化、非几何的抽象数据,如社交网络和文本的可视化。其核心挑战是针对大尺度的高维数据,尽可能减小视觉混淆,展示用户感兴趣的信息。
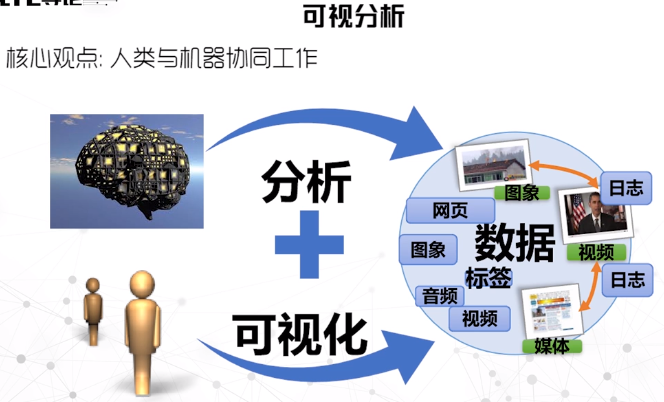
可视分析学
研究以交互式界面为基础的分析推理科学。其核心挑战是解决需要人参与理解和决策的多种实际问题。
可视化工具
Tableau
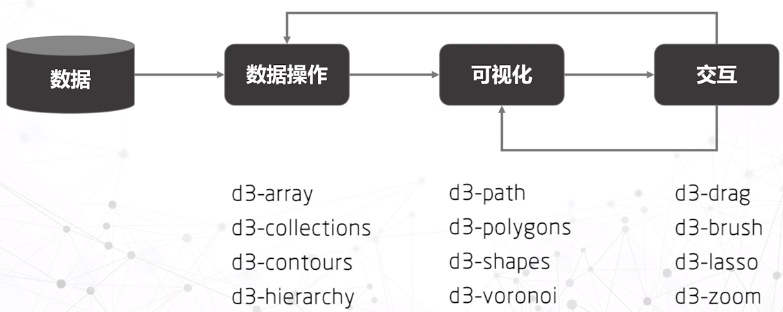
D3.js
Vega
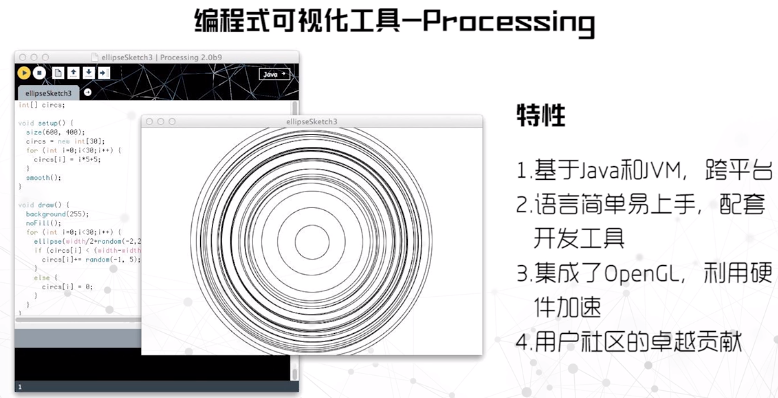
Processing
视觉感知与认知
记忆在人类认知过程中起着至关重要的作用,但工作记忆容量十分有限,可视化可以作为外部辅助来增强工作记忆。
观察物体的变化需要集中注意力,在可视化中突出变化,可以减少认知负担。
感知系统基于相对判断,而非绝对判断。使用相同的参照物或者相互对齐,有助于人们做出更加准确的相对判断。
格式塔理论
结构比元素重要,视觉形象首先作为统一的整体被认知,而后才以部分的形式被认知。
接近原则:当视觉元素在空间距离上相距较近时,人们通常倾向于将它们归为一组。

相似原则:人们在观察事物的时候,会自然的根据事物的相似性,如形状、颜色、光照等性质来决定分组。

连续原则:人们在观察事物的时候,会自然的沿着物体的边界,将不连续的物体视为连续的整体。
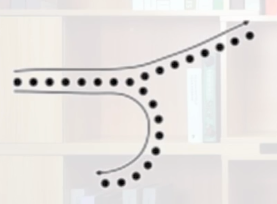
闭合原则:在某些视觉影像中,只要物体的形状足以表征物体本身,人们会很容易地感知整个物体而忽视未闭合的特征。

共势原则:一组物体具有沿着相似的光滑路径运动趋势或具有相似的排列模式时,将被识别为同一类物体。
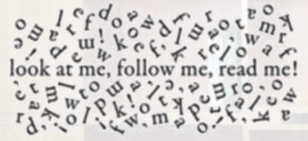
好图原则:人眼通常会消除复杂性和不熟悉性来理解被识别的物体。

对称原则:人的意识倾向于将物体识别为沿某点或某轴对称的形状。

经验原则:某些情形下视觉感知与过去的经验有关。

视觉通道:用于控制标记(常常是点、线、面)的展示特征。
- 定性/分类型:描述感知对象是什么或在哪里,适合编码分类型的数据信息。这类视觉通道主要有:形状、颜色色调、空间位置
- 定量/定序型:描述感知对象某一属性的具体数值是多少,适合编码有序型的或者数值型的数据信息。这类视觉通道主要有:直线长度、区域面积、角度、空间体积、颜色的饱和度、颜色的亮度。
- 分组型:描述多个或多种标记的组合,适合将存在相互联系的分类的数据属性进行分组,从而表现数据的内在关联性。这类视觉通道主要有:位置接近,颜色相似,显式连接,显式包围。
可视化设计:识别数据类型$\rightarrow$确定想要传递的信息$\rightarrow$选用合适的标记与视觉通道,不断迭代这个过程。
举个例子,假设现在要对班级,数学平均分,语文平均分这三个数据可视化。班级是分类数据,平均分是数值数据,如下图使用不同颜色色调(视觉通道)的点(标记)对班级编码,使用点(标记)的不同位置(视觉通道)对平均分编码,可以将所有信息展示出来。

关于数据
相异性矩阵
刻画数据对象之间的相似性,矩阵第i行第j列元素值为:第i个数据对象与第j个数据对象的距离d(i, j)。
失配比
计算类别属性的距离,计算公式:值不相等的属性个数占总属性个数的比例。
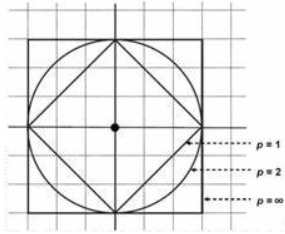
闵可夫斯基距离
计算数值属性的距离,计算公式:$d_{Mk}=\sqrt[p]{\sum\limits_{i=1}^d\left|P_i-Q_i\right|}$,p=1时为曼哈顿距离,p=2时为欧拉距离,p$\rightarrow\infty$时为切比雪夫距离$max_{i=1}^d\left|P_i-Q_i\right|$。下图是当p分别为1、2、$\infty$时,与原点距离为3的图像。
选取合适的视图对数据进行可视化可以用来清洗数据。
视图
数据轨迹:是一种单变量数据呈现方法,将自变量与因变量在图中用点呈现出来,可以直观地展现数据分布、走势以及离群异常点。
柱状图
用长方形的形状与颜色编码数据的属性,揭示数据的趋势与分布。
- 柱状图要以0为基线,上下方向绘制。
- 堆叠柱状图主要用于分解整体,比较局部。
饼状图
用环状方式呈现各分量在整体之中的比例,快速直观地传达数据中的比例信息。
直方图
对数据集的某个数据属性的频率统计,每个区间的数据之和为数据集整体。
等高线图
将相等数值所在的位置用曲线连接起来所形成的图形,反映数据的连续变化与分布情况。
走势图
通常以折线图为基础,反映简单的数据变化趋势。
- 折线图要注意选择合适的长宽比。
- 走势图需要足够小,以便于嵌入到文本中。
散点图
当数据大于二维时$\rightarrow$所有维度两两取出$\rightarrow$每对维度一个散点图$\rightarrow$所有散点图形成散点图矩阵。
热力图
有3个维度的数据,利用颜色属性,将第三个维度映射为颜色值,此时就成了热力图,可以查看三维数据的分布情况。
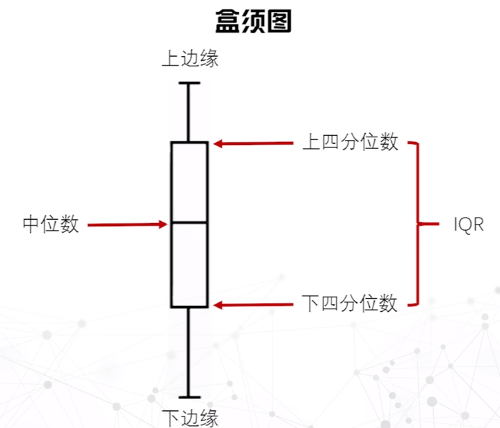
盒须图
用长方形的盒子表示数据的主体范围,通过观察盒子的长度可以很容易地看出数据分布的大致结果。
多协同视图
将多个视图结合起来,每个视图展现数据的某个方面的属性,并允许用户进行交互分析。
数据挖掘
从大型数据库、网络上或其他大型储存库中,自动地发现和提取模式、特征或知识,这些知识是非常规的或以前未知的信息。
描述型任务:通过算法(例如概念描述、关联规则、聚类模式、异常分析)从数据中挖掘特征,利用这些特征来对数据进行描述、解释和总结。
预测型任务:首先通过训练数据得到一个模型,然后将这个模型运用到新的数据集中,用来对这个数据集进行判断,得出结果。
常用方法:统计学习(回归分析、参数估计),机器学习(决策树、神经网络),传统算法(K均值、K临近)
可视化基本流程
数据获取 $\rightarrow$ 数据处理 $\rightarrow$ 任务分析 $\rightarrow$ 数据可视化 $\rightarrow$ 可视化分析(趋势、异常、特征)
What can be visualized?(数据抽象) $\rightarrow$ Why people are using vis?(任务抽象) $\rightarrow$ How to design vis idiom?
可展示数据筛选 $\rightarrow$ 可视化编码映射 $\rightarrow$ 视图与交互设计
筛选适当数据量
编码时,注意数据的语义以及用户个性特征
单试图还是多视图,交互时可采用”滚动和缩放”、”颜色映射”、”数据映射”、”细节层次控制”
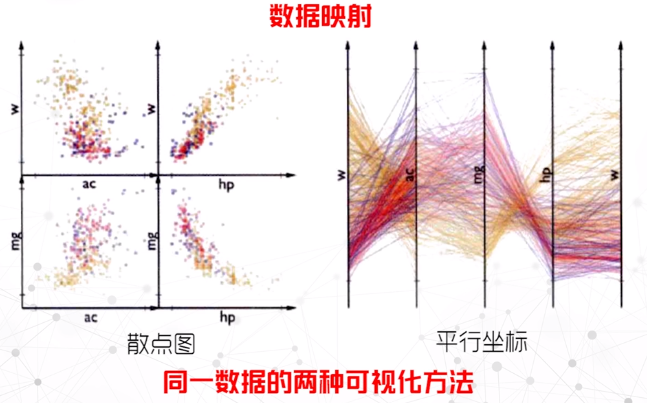
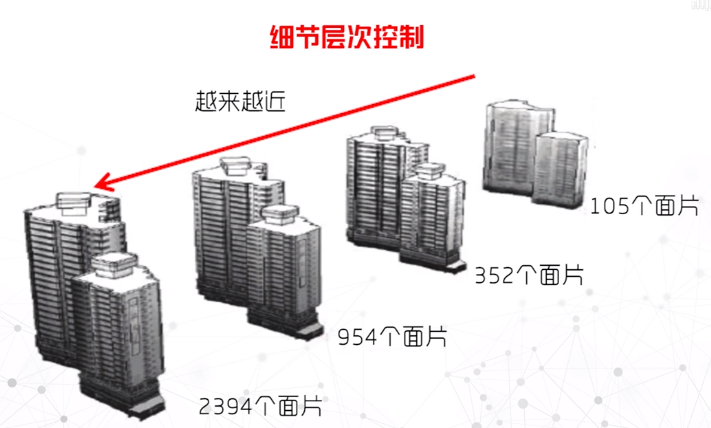
数据处理
数据归一化
基本思想:将数据按比例缩放,使之落在一个小的特定范围。
基本方法:
线性变换:$y=\frac{x-MinValue}{MaxValue-MinValue}$,值域:[0, 1]
反正切变换:$y=\frac{2\cdot arctan(x)}{\pi}$,值域:[-1, 1]
数据平滑化
基本思想:表达并观测”趋势”,劫富济贫(让低数据点和高数据点尽可能均匀分布在拟合曲线周围)。
基本方法:一次方程、指数函数、多项式曲线、自定义曲线。
数据采样
基本思想:获取或处理全部数据集代价太高,所以选出具备原始数据特征的数据。
分箱
基本思想:将一些连续值分组装进一些”小箱子”的办法。
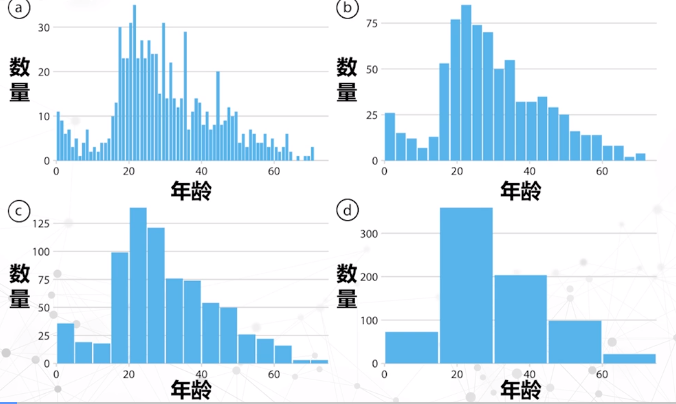
降维
基本思想:将数据从多维的空间投影到二维或三维的空间。
基本方法:主成分分析、多维尺度分析、t分布随即近邻嵌入、自组织映射、等距特征映射。
聚类
基本方法
K均值聚类(给一些参考点对数据归类,计算均值,然后把均值均值所在的点作为新的参考点再重新归类)
高斯混合模型
- 基于密度的聚类算法
- 层次聚类
- 谱聚类
编码
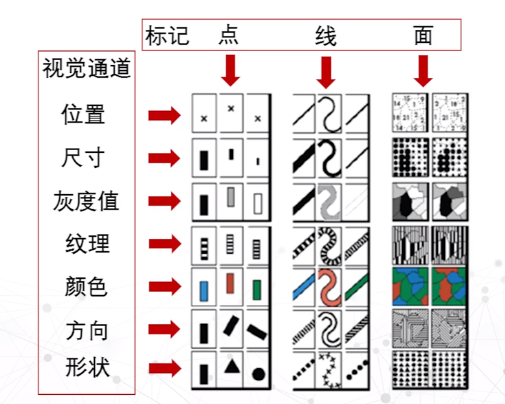
编码的表现力
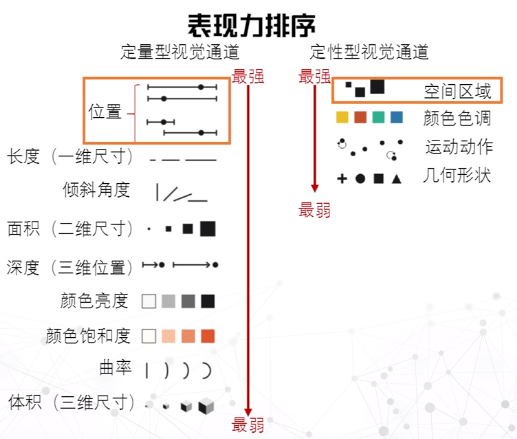

表现力的衡量因素:精准性、可辨认性、可分离性(差异)、视觉突出(突出)
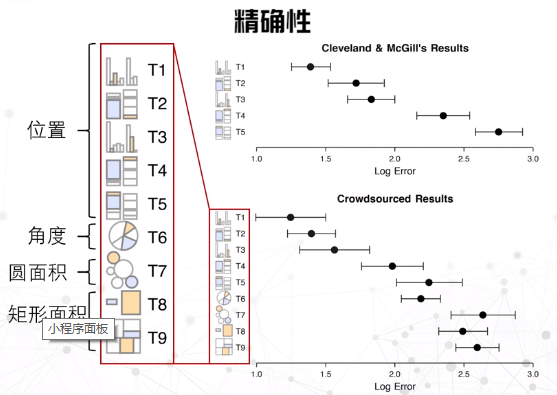
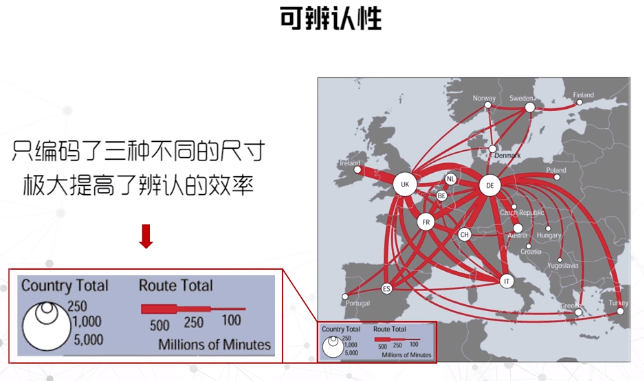
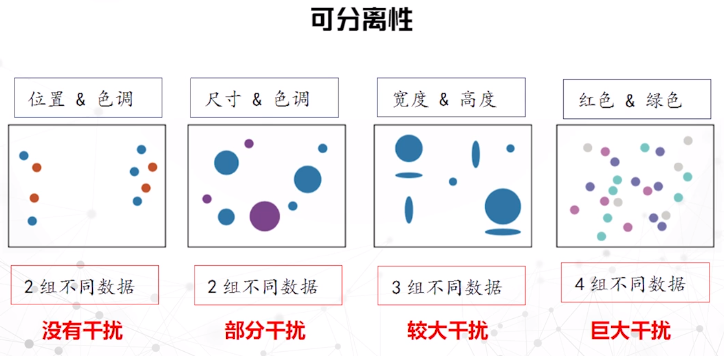
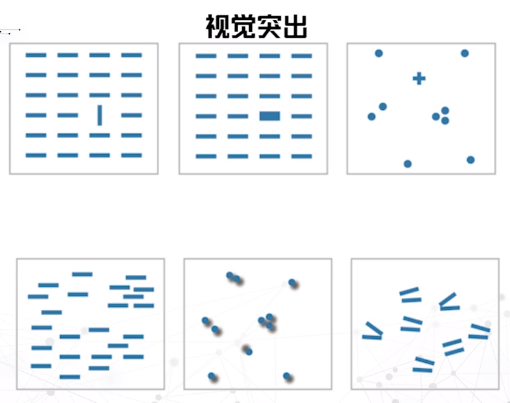
空间数据可视化
表格数据
存储离散的对象,仅代表空间中特定点的值。
场数据
对连续的空间进行度量,场数据大多与空间、时间、地理位置有关。
标量场
标量场在每一个数据点处只有一个值,向量场在每一个数据点处是一个向量。
一维标量场:沿空间某一路径采集的数据。一般采用二维坐标图或折线图来可视化
二维标量场:分为平面型(医学影像),和曲面型(地球表面温度)
- 复杂的曲面需要在三维空间中可视化,简单的曲面可以在二维平面可视化(地球坐标用经纬度来表示)
三维标量场:记录三维空间中的物理属性及其演化规律,包括医学断层扫描、地震科学模拟等。
转化为低维(如等值面提取、直接体绘制等)
等值面提取:
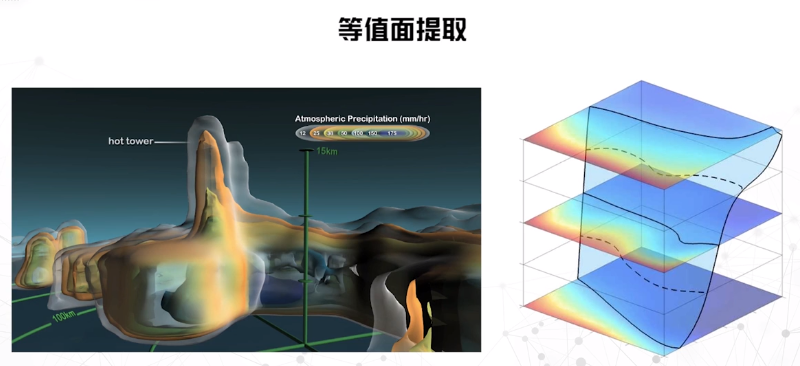
可使用移动立方体算法来计算等值面
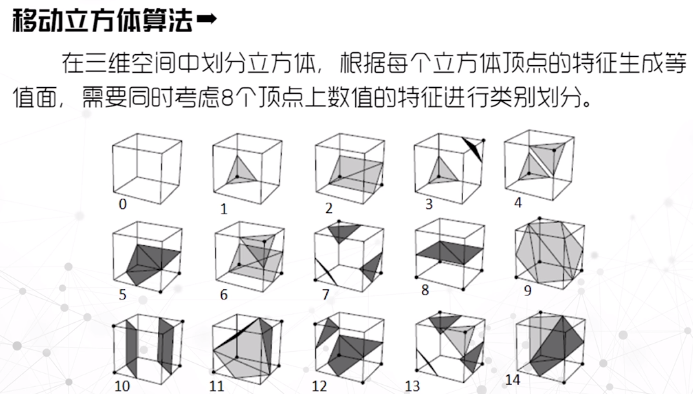
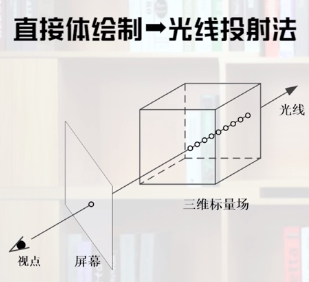
直接体绘制:
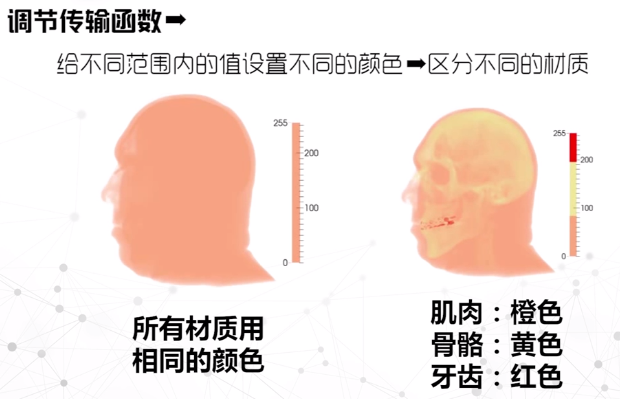
矢量场
- 标记法:用方向的标记编码不同位置上的矢量的方向和大小。
- 积分曲线
- 流线:静态场生成的积分曲线
- 迹线:动态场中产生的积分曲线
- 脉线:从同一个点不断发射新的粒子
张量场
常用于表示物理性质的各向异性。
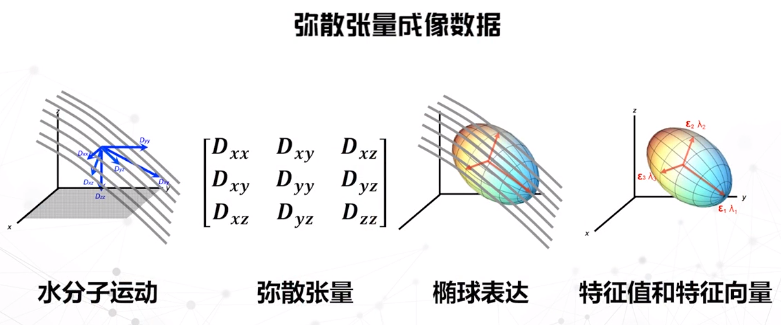
- 指数法:将每一个张量转化为一个标量,运用标量的可视化方法进行展示。
- 标记法:类似二维场数据中使用的标记法,只是使用的标记更加复杂,通常用一些图形来表达张量。
混合绘制
核心难点:正确显示不同类型绘制对象间的层次关系和透明颜色的叠加。
地理信息可视化
描述了对象在空间中的位置和属性。


地图投影
等角度
投影面上某点上两个方向线所夹的角=地球椭球面上相应的角度
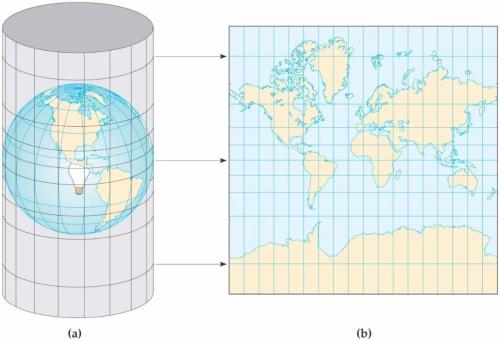
墨卡托投影(正轴等角圆柱投影
- 离赤道越远,面积变形越明显
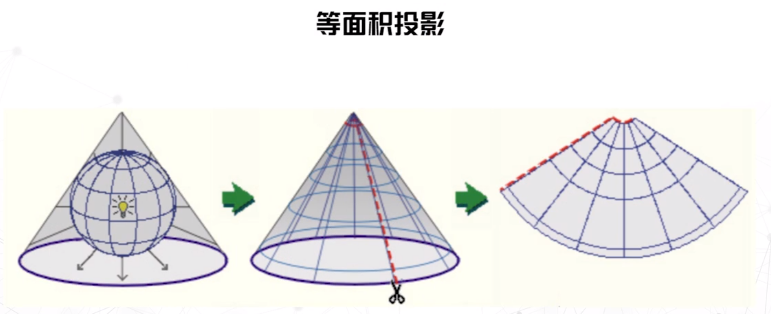
等面积
亚尔勃斯投影
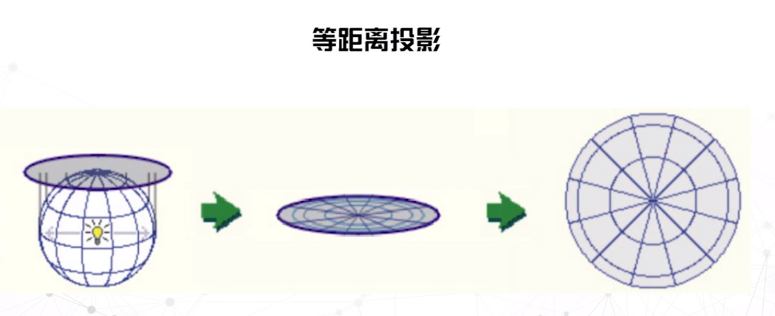
等距离
方位角投影
可视化变量
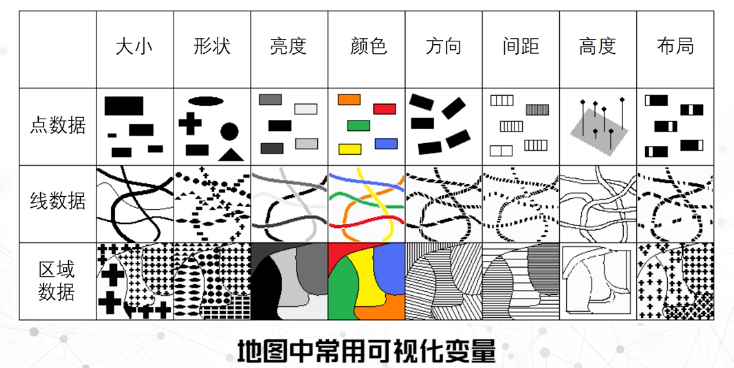
考虑到地图中可视化变量的多样性,地理空间数据可视化需要谨慎考虑各元素的类别、数据的规范性和空间聚集性来有效地展示数据信息。
点数据
如地图中的地点或建筑物等。
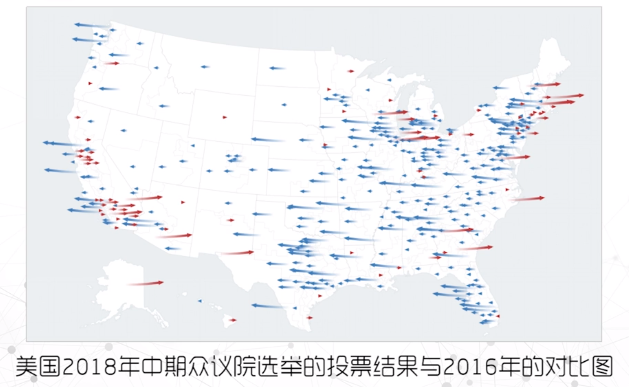
案例1:用颜色编码不同年,用点的方向和长度编码该年投票的民意变化。
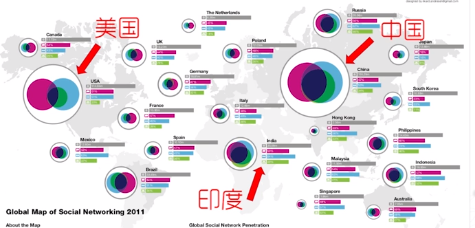
案例2:下图是各国社交媒体模式的可视化,用颜色编码社交媒体的三种模式(消息传播、内容分享、社区创建),用文恩图表示三者的交错关系,用圆的大小编码各模式使用人数的多少。可以看出,中国的社交媒体使用方式和美国不同,而和印度类似。
当点数据过多时,可使用”采样”、”聚合”来避免数据点之间的覆盖。
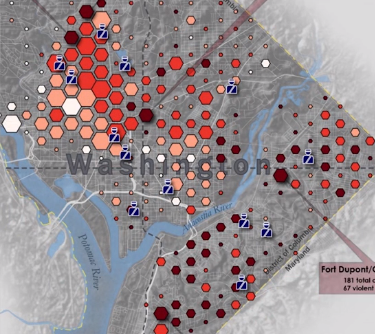
案例3:下图是华盛顿地区暴力事件的可视化,用六边形网格来聚合该地区的暴力事件,用六边形的大小编码暴力事件发生的多少,用颜色的深浅编码暴力事件的严重程度。可以看出,左上角的暴力事件频发,但武力冲突较少,右下角暴力事件相对少,但武力冲突占比较多。
线数据
如地图中两点的行车轨迹,或者河流等。
案例1:用连线编码两个城市之间的好友关系,用黑、蓝、白三种颜色编码两个城市中好友的数量。我们发现长的连线大多是蓝色的,短的连线大多是白色的,说明了大多数的朋友都居住在同一个地方或附近地区。

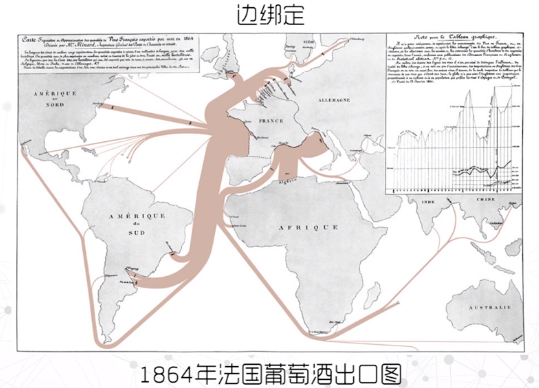
案例2:用线编码葡萄酒出口的路径,用线的宽度编码该路径葡萄酒出口的数量。通过边绑定,将葡萄酒出口的走势与出口的数量绑定在了一起。
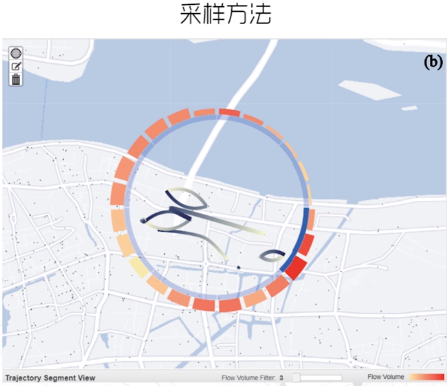
案例3:这个案例提供了大规模轨迹渲染的另一种可行方法:对轨迹数据进行采样,选取几条具有代表性的轨迹展示,并用线条的颜色编码轨迹的方向,另外红色的柱状图展示了该地区一天24小时的轨迹流量。
区域数据
区域数据的属性往往是一些统计值:如人口密度、人均收入、犯罪率等等。因为属性的多样性,以及区域形状的复杂性,可视化的方法各不相同。
等值线图
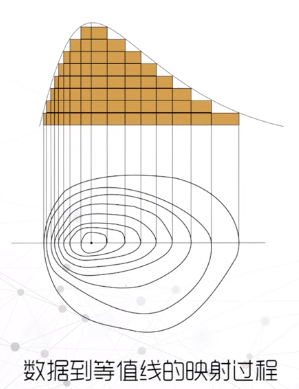
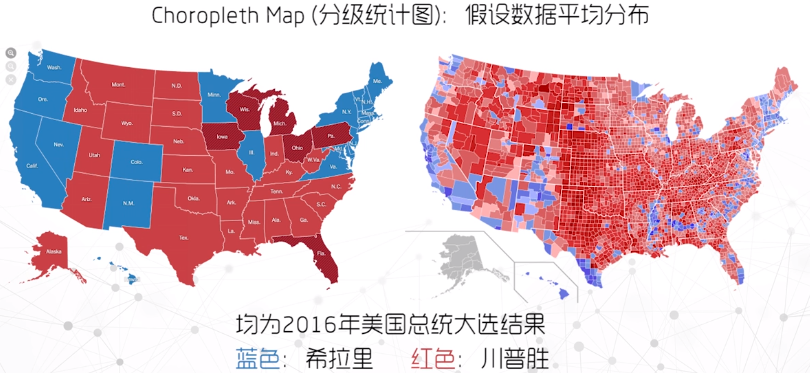
分级统计图
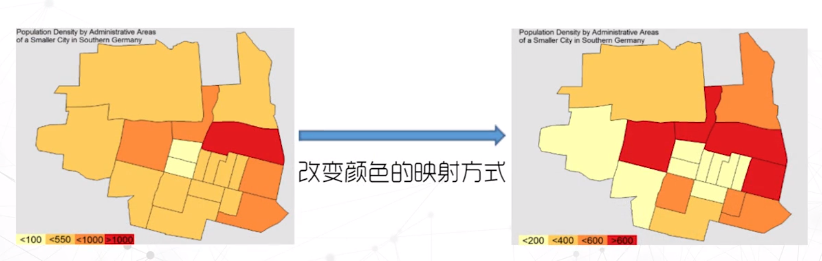
包括统计值的区域数据
用颜色代表数值
缺点:假设数据在区域内平均分布;面积越大数据占比越大的视觉误导
显然由于分区数量的增多,右边这幅图更详细地展示了数据分布信息。
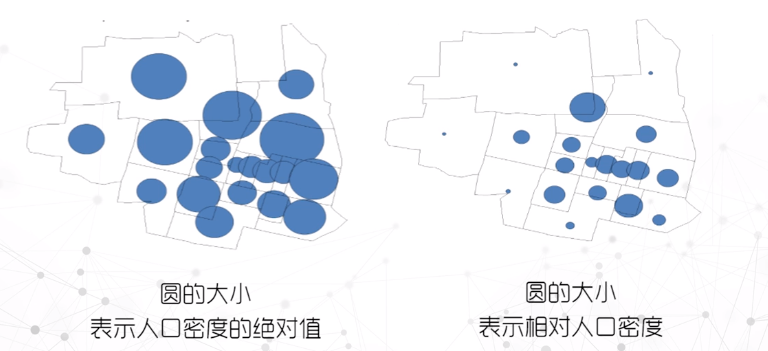
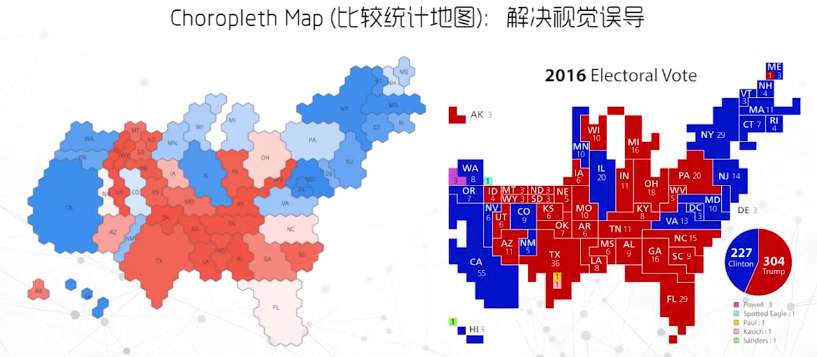
比较统计图
案例1:按照每个州的选举人数重新缩放每个州,然后按照每个州的形状作统一的规划,例如下图用六边形或矩形拼接成整齐的图案,现在地图基本上反映了每个候选人到底在每个州赢得了多少选票。
规则形状地图
案例1:也可以使用规则的形状来反应地区某个属性值。

多元关系图
线集合图、气泡图分别采用”连线”和”集合”等方法展现区域属性之间的多元关系。
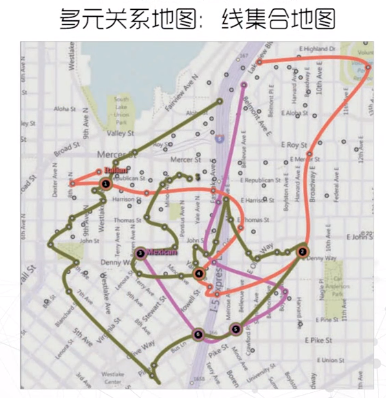
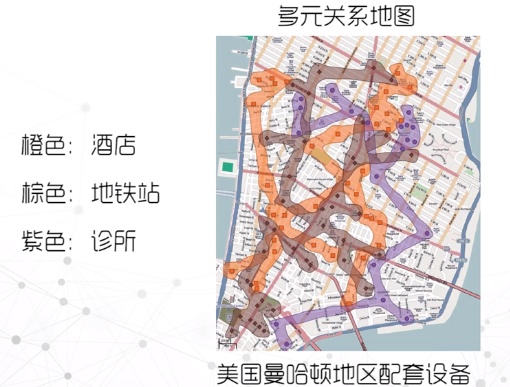
其他
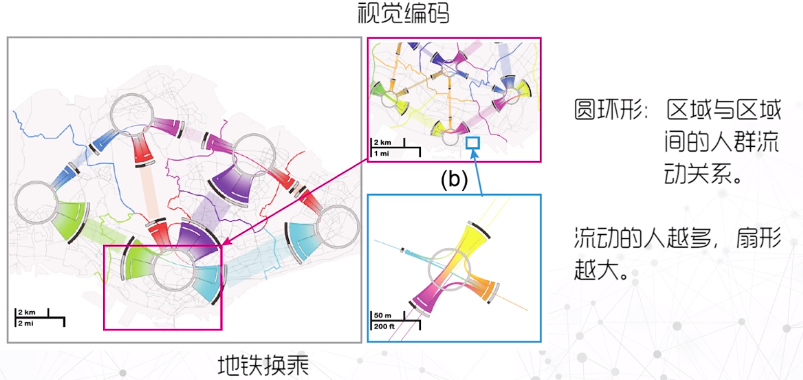
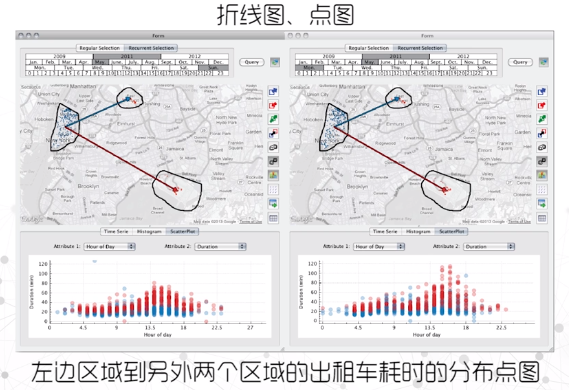
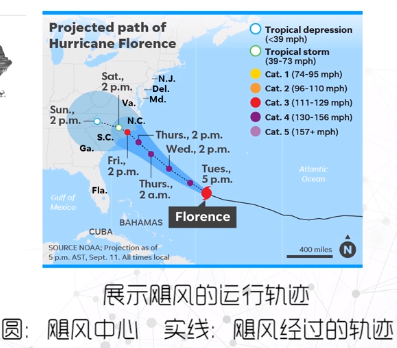
气象数据
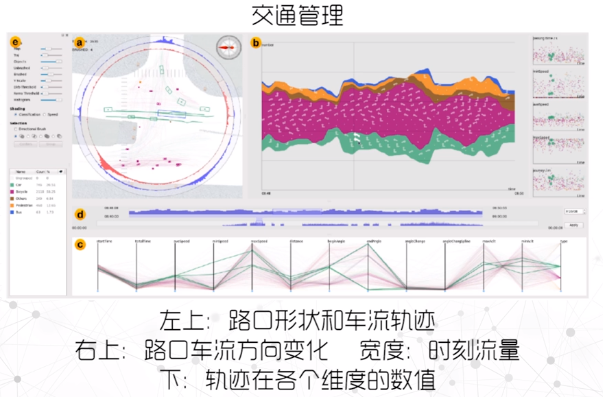
城市数据
- 数据量大,多源异构
- 需满足多样的分析任务
- 需表达让用户更容易发现数据特征的数据
多源数据融合
- 数据维度不一,且属性各异
- 需要针对每一种数据源设计高效的数据存储和计算方法,建立各个数据对象在时空上的关联
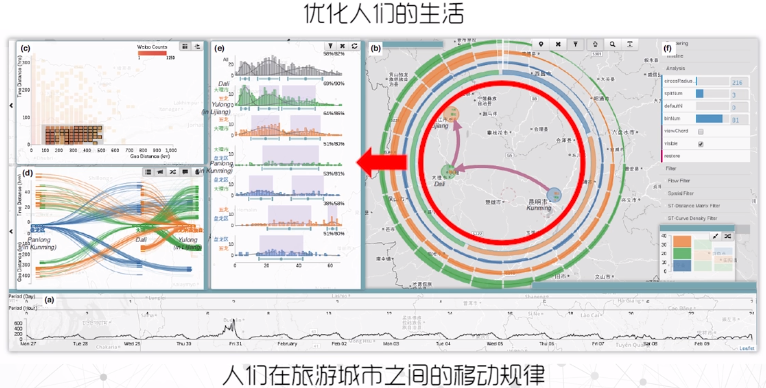
案例:通过微博、手机轨迹信息和出租车数据三个数据源,帮助顾客找到出租车上的手机。
- Searching posts about “lost” from the Microblog data.
- Manually extracting the names of two POIs from the posts.
- Exploring the street view and confirm the origin.
- Searching the locations of two POIs by their names.
- Performing an OD query.
- Analyzing the results and finding the taxi passengers get on.
时变数据可视化
随时间变化的、带有时间属性的数据。
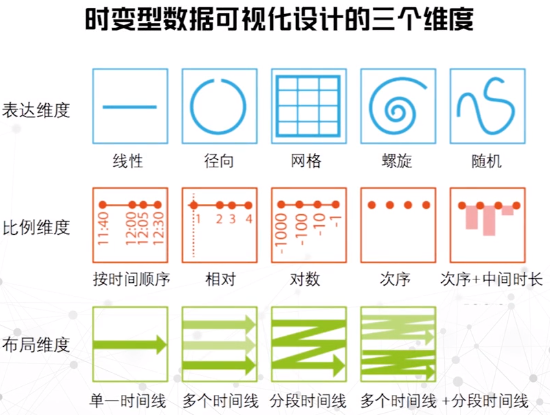
表达维度
决定了如何将时间信息展现在可视化结果中。
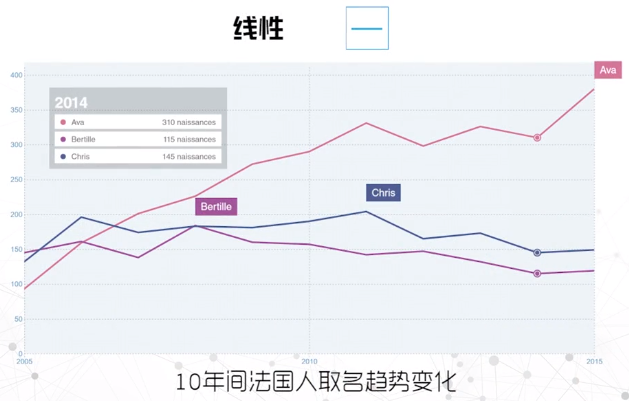
线性
- 以典型的阅读方式呈现内容
- 将时间数据作为二维的线图显示:x轴表示时间、y轴表示其他变量
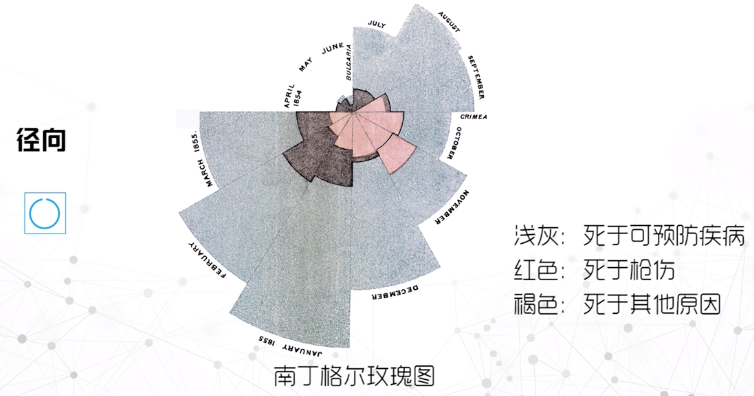
径向
将时间序列编码为弧形,沿圆周排列
适合呈现周期性的时变数据

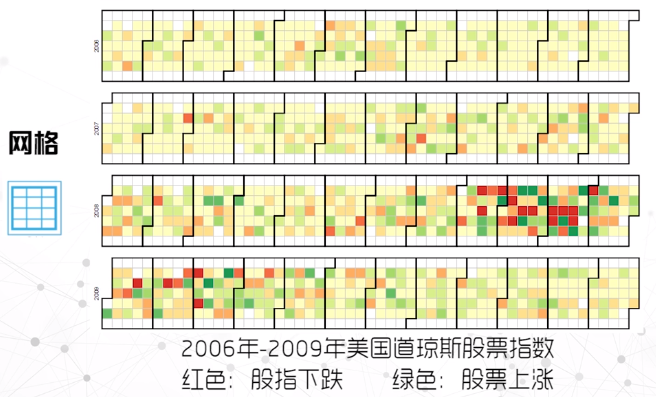
网格
和日历相对应,一般采用表格映射
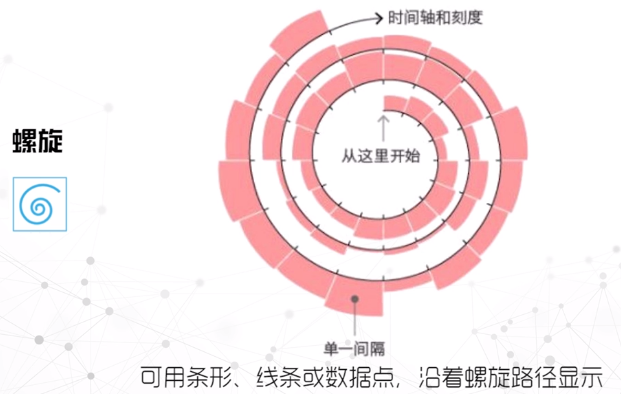
螺旋
随机

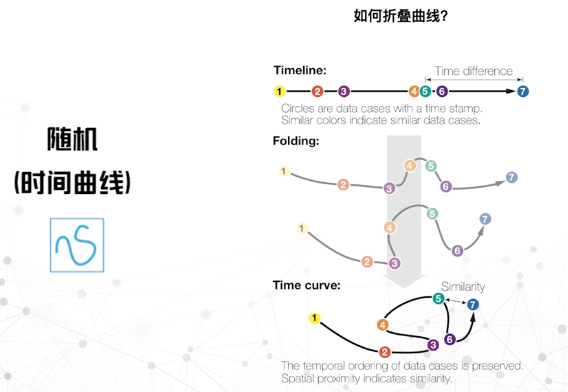
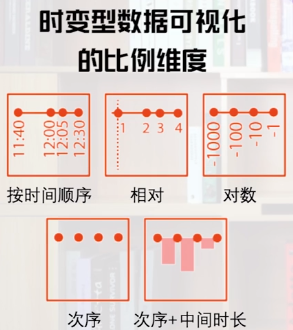
比例维度
用来表达事件之间的关系。
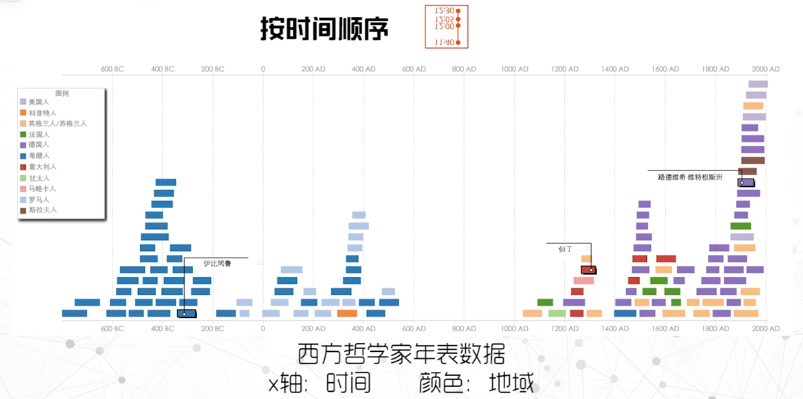
按时间顺序
可以被用来表示事件之间的距离,事件的持续时间。
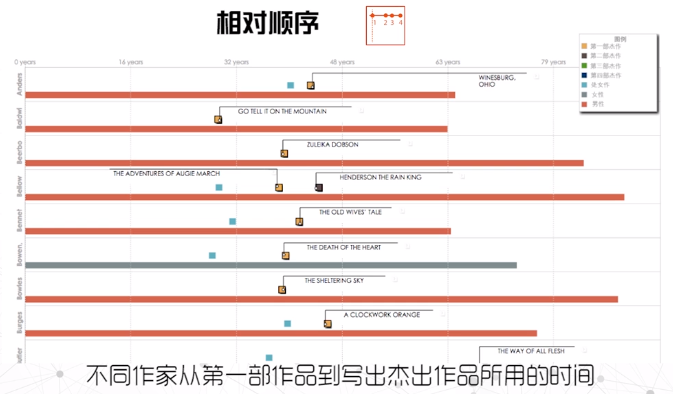
相对
存在一个基线事件在时间零点,可以被用在多时间线的对比
对数
对数的比例强调了最早的或最近的事件,适用于长范围或不均匀的事件布局。
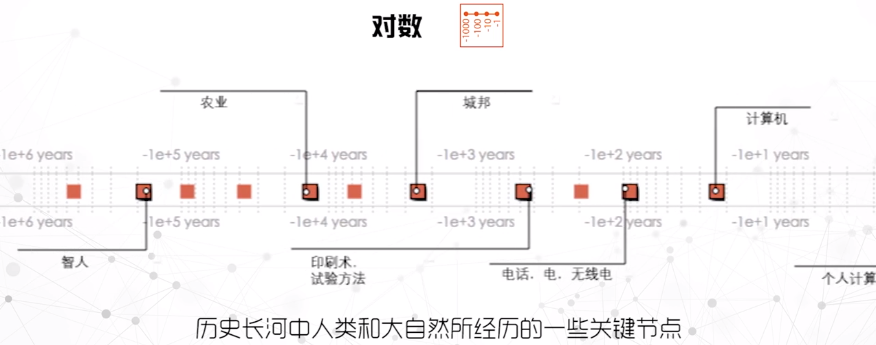
次序
按次序的比例中持续事件之间的距离是相等的,只表达事件的顺序。

次序+中间时长
可以用来表达长时间和不均匀分布的事件。

布局维度
表示事件组之间的关系。
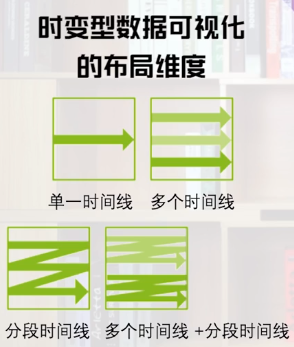
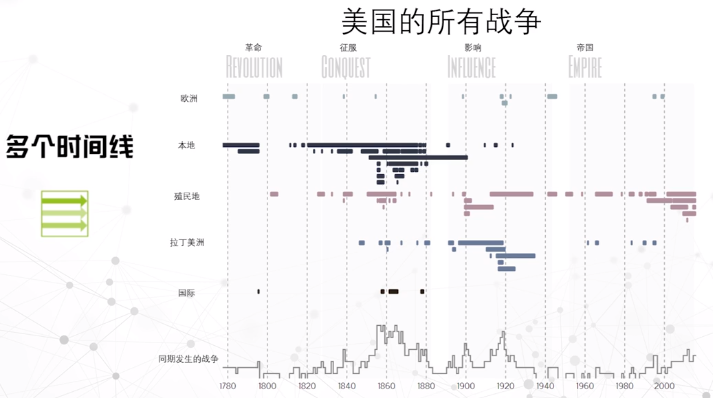
单一时间线

多个时间线
根据不同属性,分成多个时间线,可以用来作比较。
案例:下图描述了各地战争的数量和持续时间,最下面的数据表示当时同期发生的美国参与的战争数。
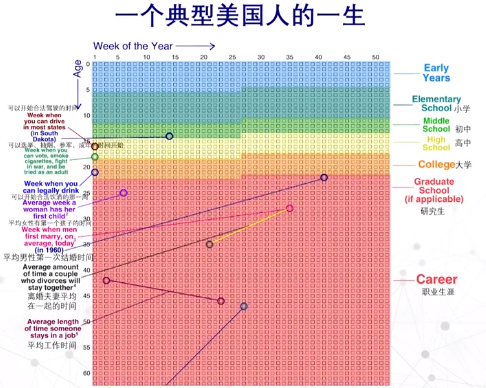
分段时间线
一条时间线被有意义地进行划分,进行另一种形式的比较。
多个时间线+分段时间线
指不同属性时间线加上分割的时间段,可以进行多种形式的比较。
多变量时变数据
基于线
高维 抽象的 时变 非空间 数据的可视化
- 高维曲线采样
- 对高维采样曲线分段
- 用降维方法将高维曲线投影到二维空间
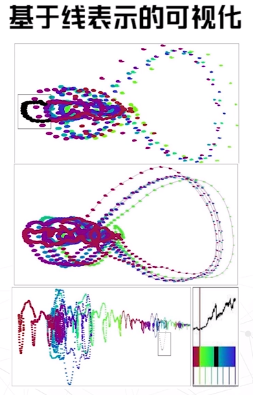
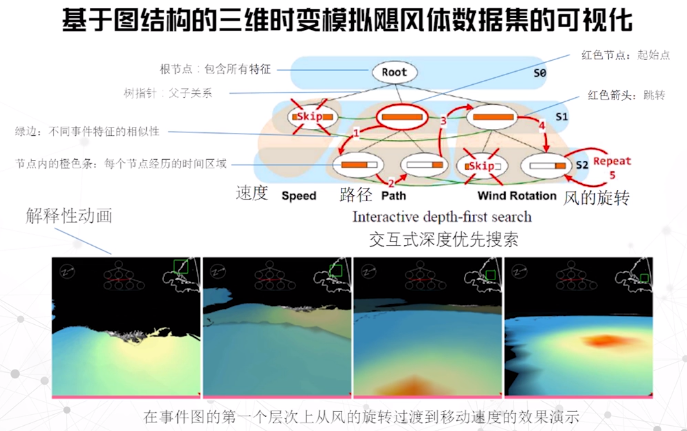
基于图
基于事件的时变型数据可视化
- 从数据中找到事件
- 对事件分类并检测事件
- 将检测到的事件进行可视化
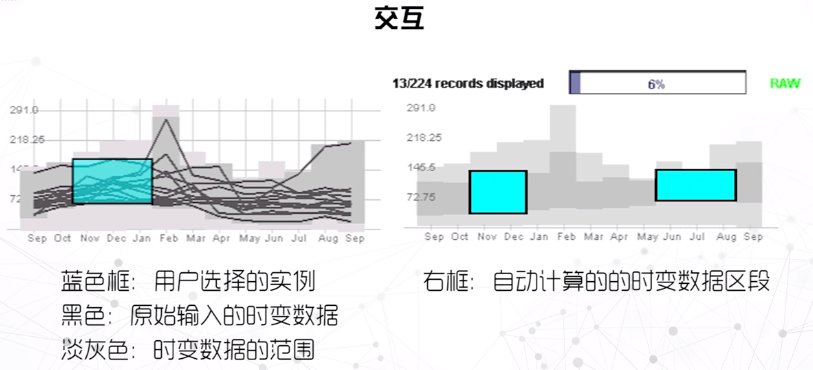
交互
TimeSearcher
- 直接指定时变趋势模式
- 操纵时变型数据集
- 基于实例查询给定的时变趋势模式
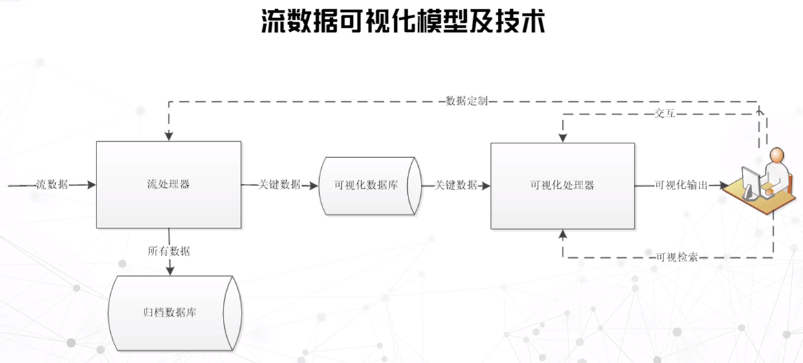
流数据
移动通信日志、网络数据、高性能集群平台日志、传感器网络记录、金融数据等。
监控型:用滑动窗口固定一个时间区间,把流数据转化为静态数据,数据更新方式可以是刷新,属于局部分析。
叠加型/历史型:把新产生的数据可视映射到原来的历史数据可视化结果上,更新方式是渐进式更新,属于全局分析。
系统日志监控流
- Splunk
- Loggy
- Flume
- LogTool,通过分析数据包的不同ip地址和端口,判断用户正在使用的网络程序或者服务。
案例:通过分析下图用户一天的”上行流量”、”下行流量”、”HTTP请求数量”三个属性,可以判断网络流量是不是由用户浏览网页引起的。
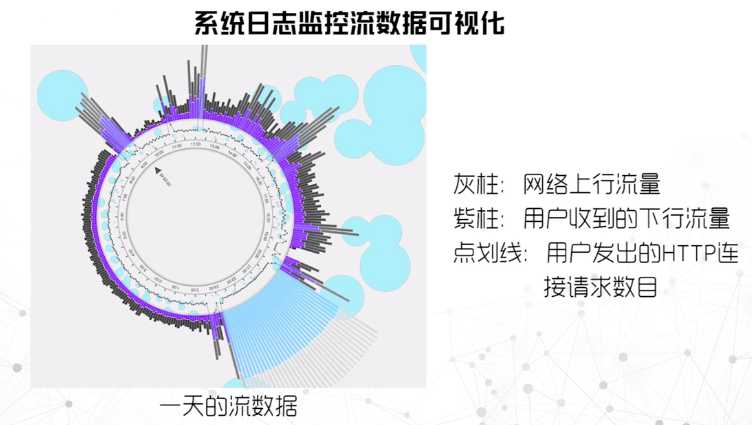
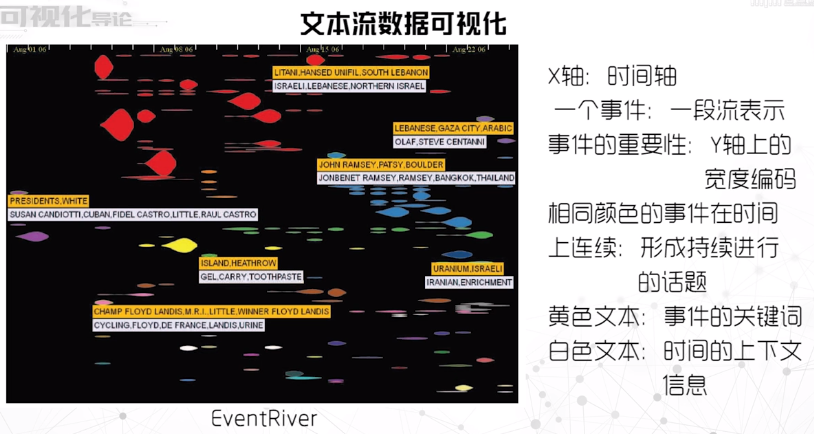
文本流
- 从事件角度对文本进行可视分析,挖掘时间的发生、发展及变化。
- EventRiver首先采用增量式聚类算法从一系列事件中提取热门话题,然后用河流的隐喻将事件的语义和上下文在一个布局界面中自然的表达出来。
树结构可视化
表达个体之间的层次关系
结点链接法
- 用点表示树的结点,用点链接表示结点之间的关系
- 核心问题:如何在屏幕上放置结点,以及如何绘制结点之间的链接关系
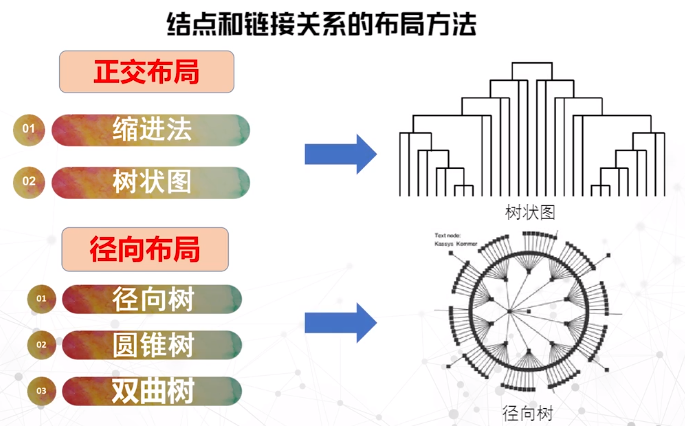
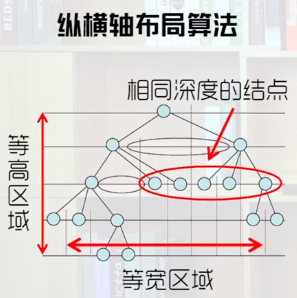
正交布局
- 结点按照水平或垂直对齐
- 布局与坐标轴一致
- 缺陷:不合理的长宽比,造成屏幕空间浪费
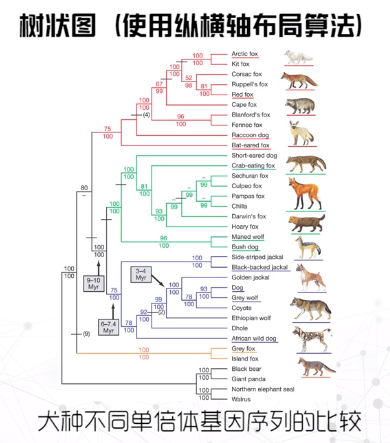
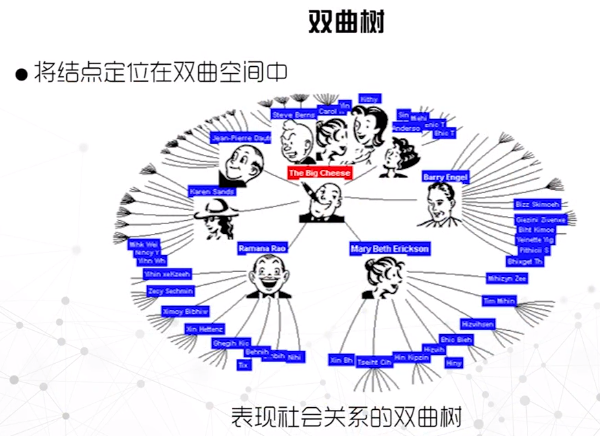
径向布局
根结点位于圆心
结点到圆心的距离对应它的深度
越外层的同心圆越大
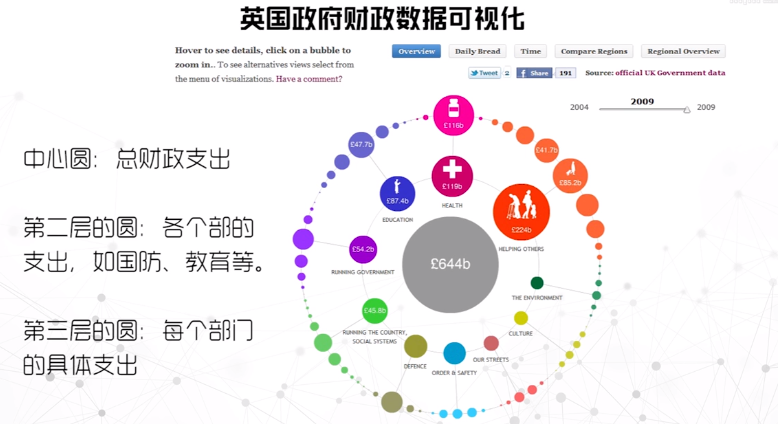
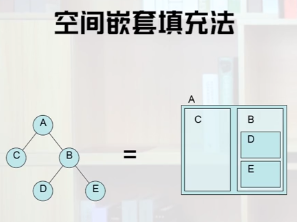
空间嵌套填充法
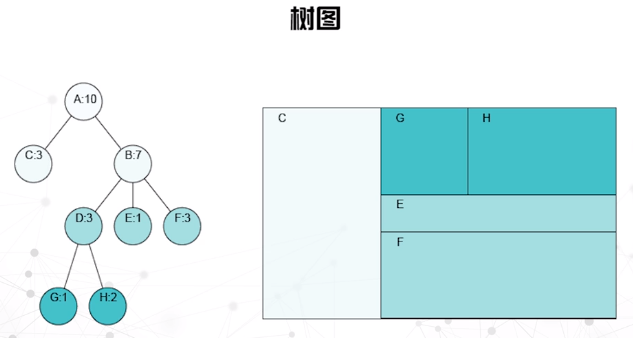
树图
- 用矩形表示结点
- 假定叶结点具有与大小相关的属性
- 父结点的大小是子结点大小的总和
- 空间利用比结点链接法更好,使用颜色和大小来编码
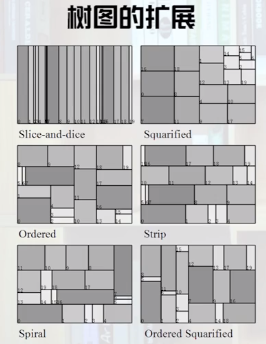
树图的切分算法如下:

旭日图相比树图可以显示中间层级的结点。
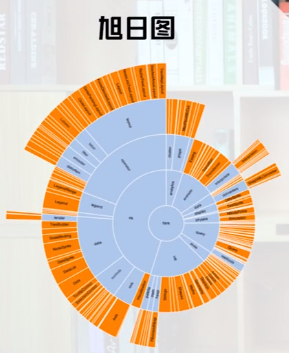

混合方法
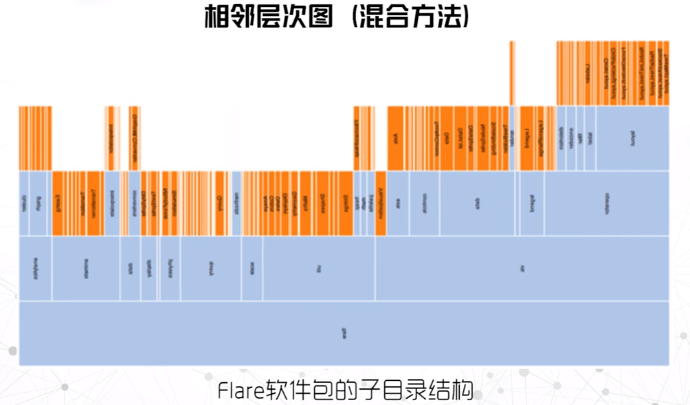
相邻层次图
- 相邻结点的位置关系编码了结点的层次关系,结点的长度或面积可以编码结点的属性或者权重
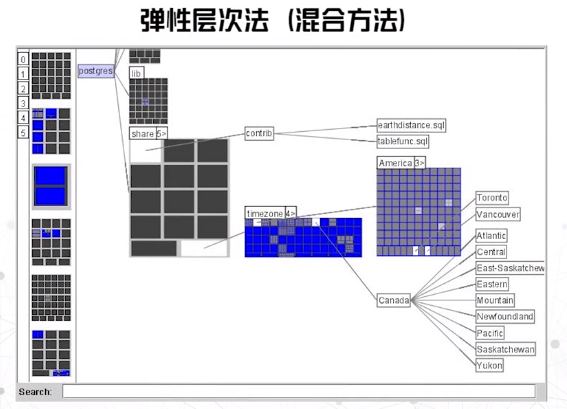
弹性层次法
- 中间层次结点用树图形式表达,叶结点呈现数据细节
图结构可视化
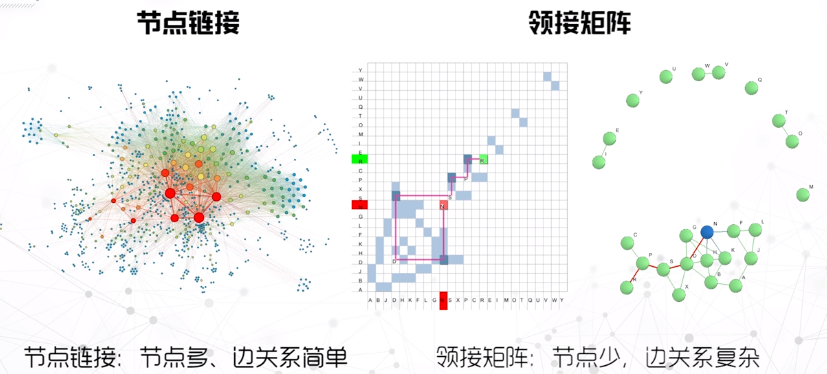
节点链接
力引导布局
- 减少布局中边的交叉,保持边的长度一致
- 只保证了局部小范围最优,全局来看可能并不最优
多维尺度布局
- 可以保持数据之间的相对位置不变,更便于整体把控

其他布局
邻接矩阵
- 对应矩阵和节点顺序有关

其他方法
传统方法的可视化会形成视觉混杂度,并阻碍人们对真实数据的认知。
图简化
- 简化图的复杂程度
- 带来细节信息的丢失
基于点
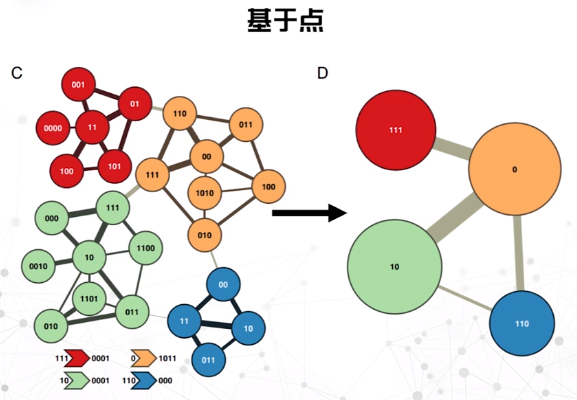
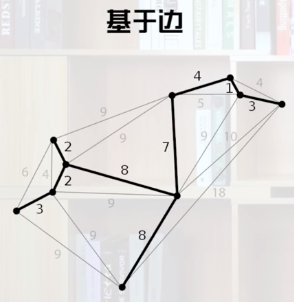
基于边
- 最常用的方法是生成树,即用一条路径来连接所有节点
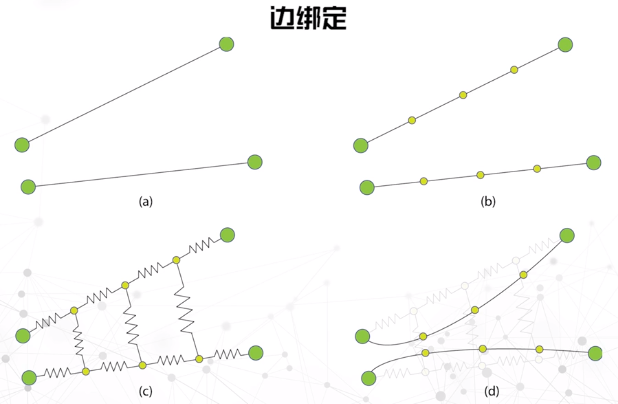
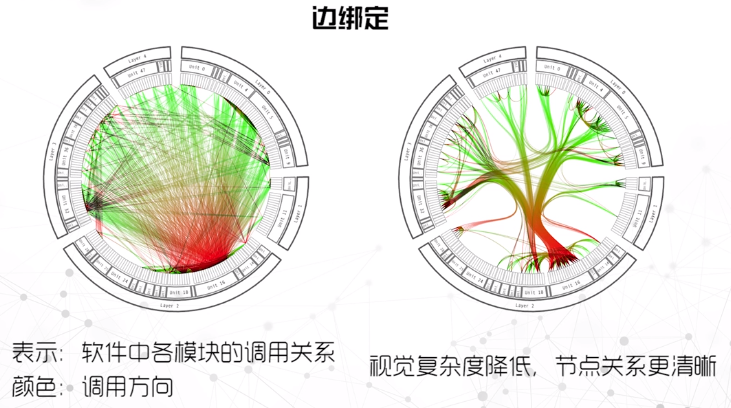
边绑定
- 在保持信息量不变的前提下,将图上互相靠近的边捆绑成一束,达到化繁为简的效果。
动态图
- 节点或边的数量不断更新变化
动画法
- 两帧之间的图以动画的形式平滑过渡
- 只能显示相邻时刻动态图的变化,不能对整体时间有概览
案例:蓝色表示新增的节点和边,红色表示将要消失的节点和边。
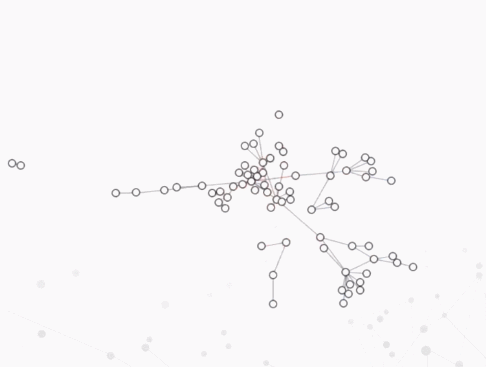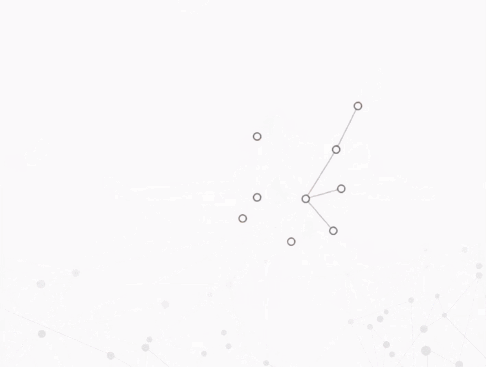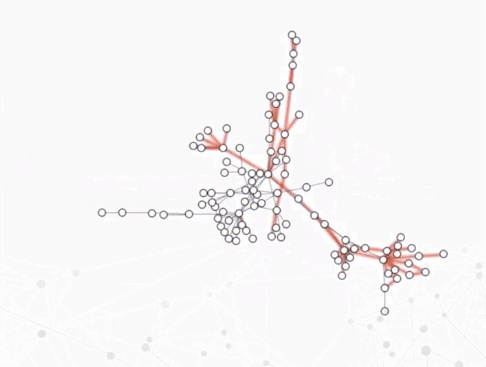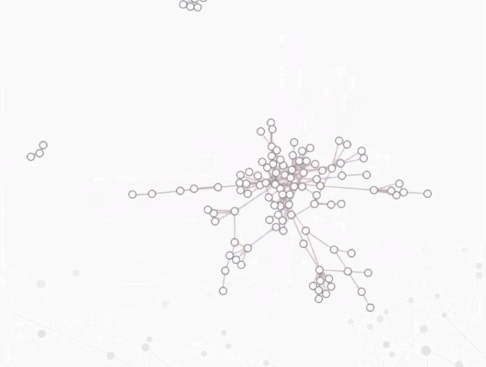
时间轴
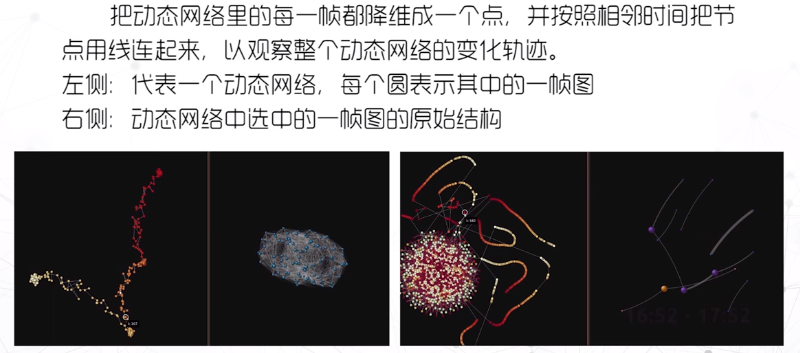
- 把动态图中的每一帧都直接展现出来,并按照时间顺序摆放,更注重时间特性上的分析。
- 难以显示大规模的动态图。
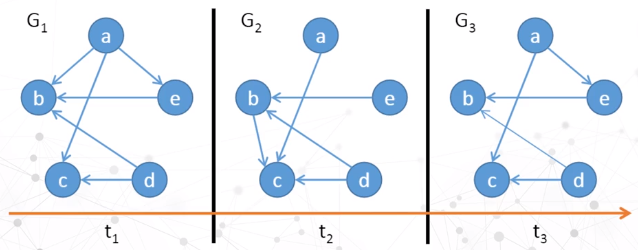
把每帧的节点聚类,把变化比较小的相邻的帧合并,减少数据规模,突出关键帧和关键结构

其他方法
可视化工具
Gephi
- 支持多平台复杂网络分析
- 进行简单的可视分析
Cytoscape
- 图编辑功能强大
Palantir
- 集成多源数据并进行可视化
IBM System G
- 集成图数据库,图数据分析,图数据计算,图可视化
Linkurious
- 社交网络分析
NodeXL
- 支持Microsoft Excel
Pajek
- 大型网络分析
文本数据可视化
- 总结展现文本中的内容
- 展现内容之间的内在关联
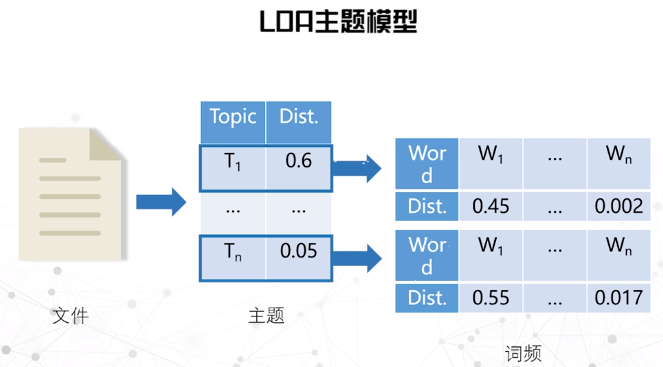
预处理 $\rightarrow$ 特征提取(词频向量、LDA主题等) $\rightarrow$ 测量(相似性计算) $\rightarrow$ 布局 $\rightarrow$ 可视设计 $\rightarrow$ 交互设计
基于关键词
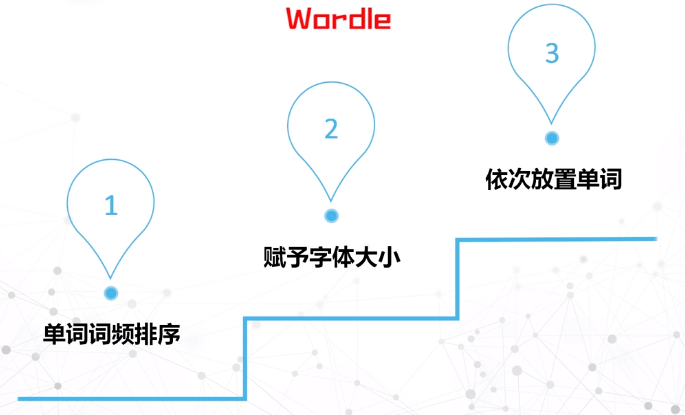
- 检索关键词并以模式排列
- 用颜色和大小编码
wordle

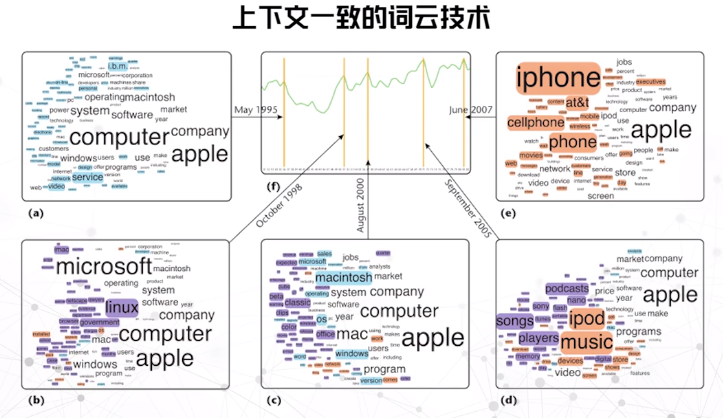
上下文一致的词云技术
语义相关或相近的词总会出现在相近位置

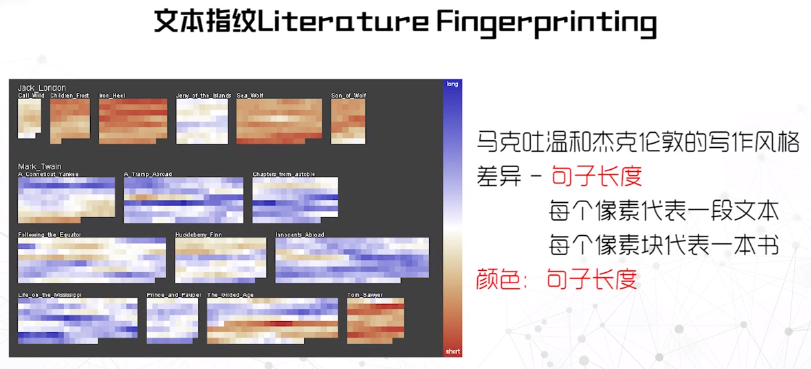
基于特征
特征有:
- 平均句子长度
- 词汇量
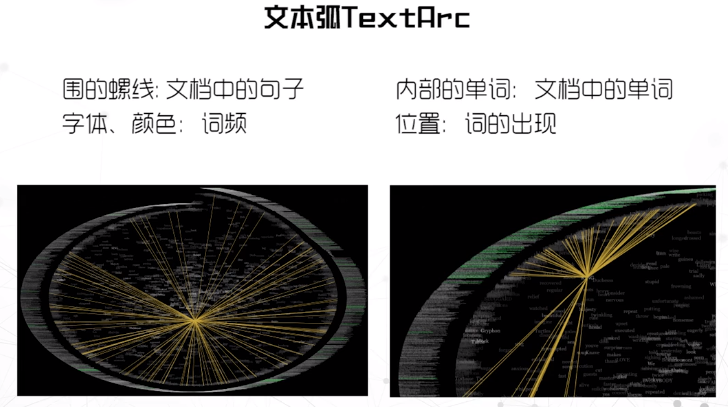

时序文档
- 将文档集合按时间划分
- 对文档按时间段进行可视化
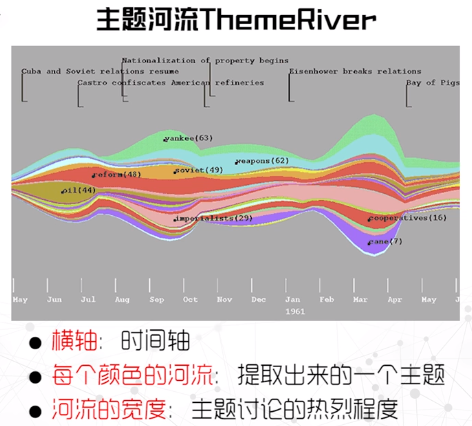
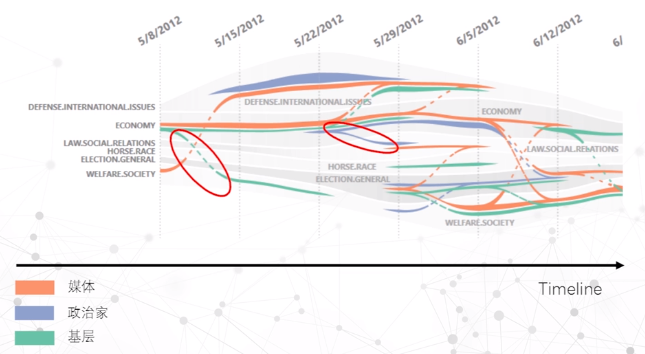
文本关系
文本关系:
- 句子之间(短语之间)
- 文档之间
- 对单个文档定义特征向量
- 计算文档间的相似性
- 采用投影技术呈现文档集合的关系



星系视图:
- 将每个文档看成一颗星星
- 将文档投影成点集
- 点与点之间的距离与文档主题相似性成正比

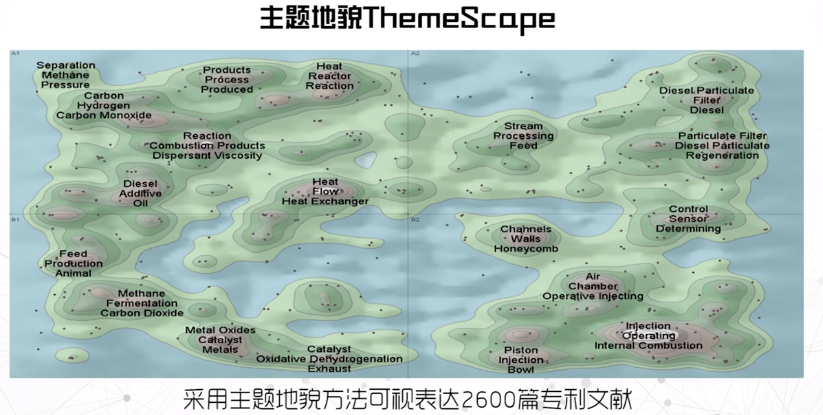
主题地貌:
- 用等高线展现相似文档的分布
- 山体高度:文档位置分布的疏密程度
- 等高线和颜色:文本分布的密度
- 文档越相似,则点分布越密集
高维数据可视化
高维:数据的组成有两个及以上的维度
- 增加视觉通道
- 多协同视图
- 数据降维

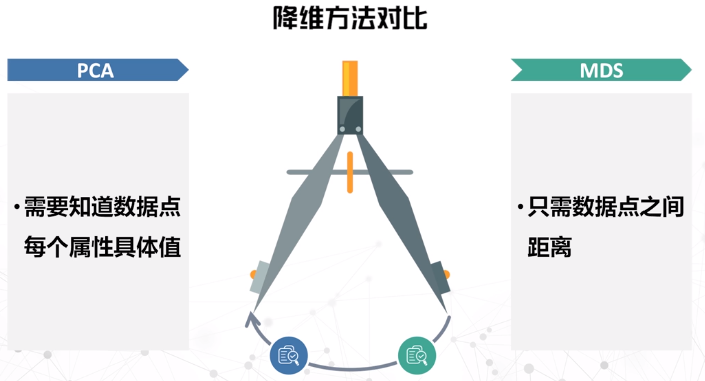
数据降维
- PCA主成分分析
- MDS多维尺度分析
协方差
- 表示两个维度的相关性,协方差为0,两个维度不相关
- 内积除以元素个数

可视化方法
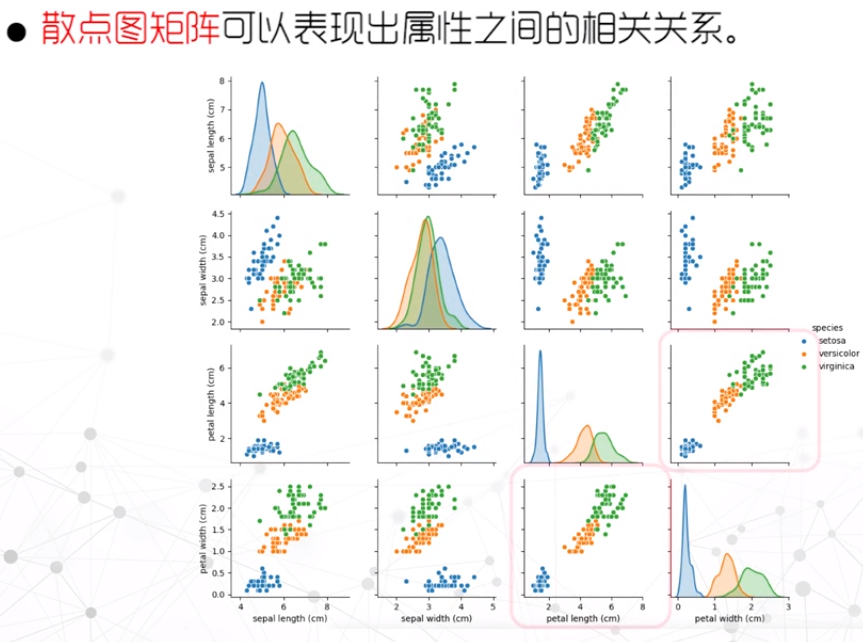
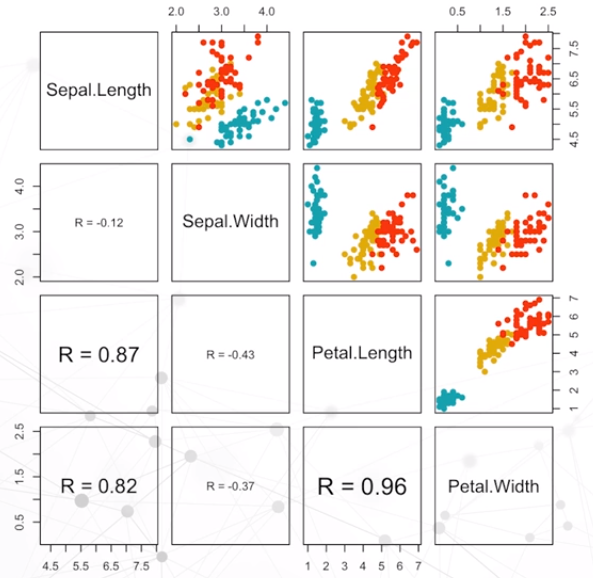
散点图矩阵
- 只能反应两两之间的关系
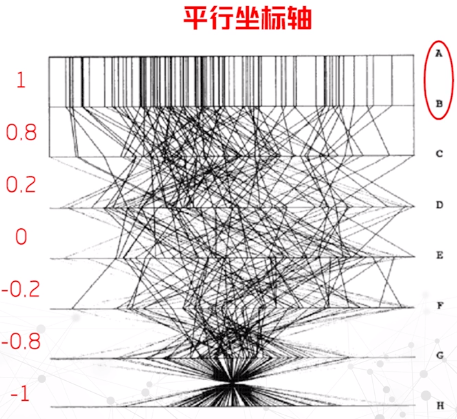
平行坐标轴
- 每个轴对应一个属性,一条折线代表一个数据
- 折线反映两两属性的相关程度
- 对非相邻属性之间的关系的表现较弱
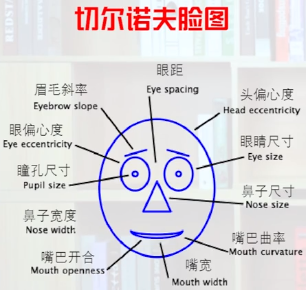
基于图标
- 选择易于感知的视觉元素
- 映射必须直观易懂


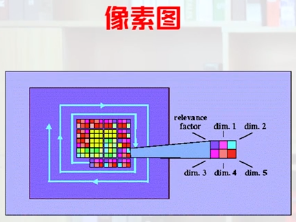
像素图
- 每个多维数据点用一系列像素组成的矩形来表示
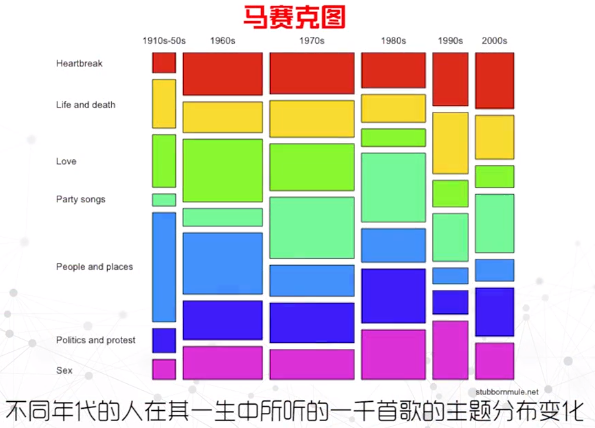
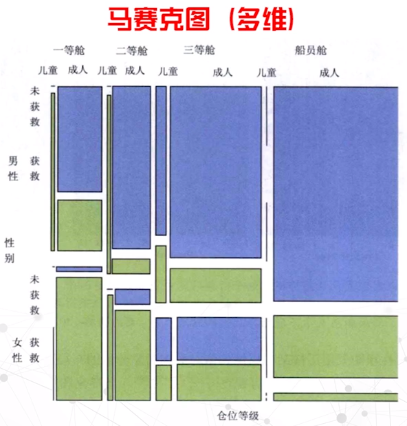
马赛克图
- 颜色编码主题(是否生还)、面积编码主题的比例(男性或女性生还的比例)
- 展现数据不同类别不断细分下的分布规律,不能将详细的数据点可视化出来
交互
概述

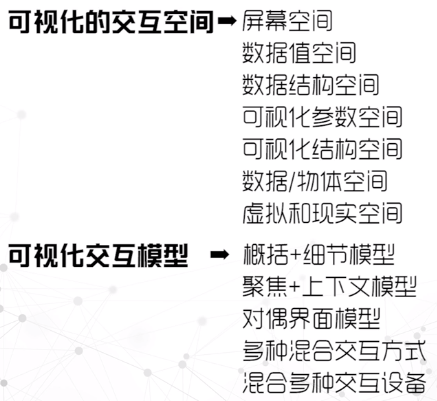
交互空间与模型

可视化工具
交互式
Power BI
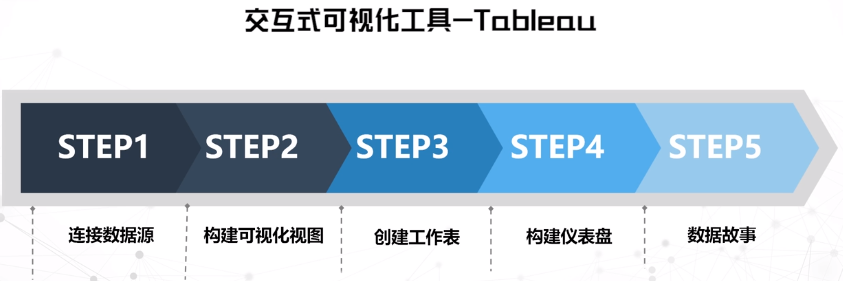
Tableau
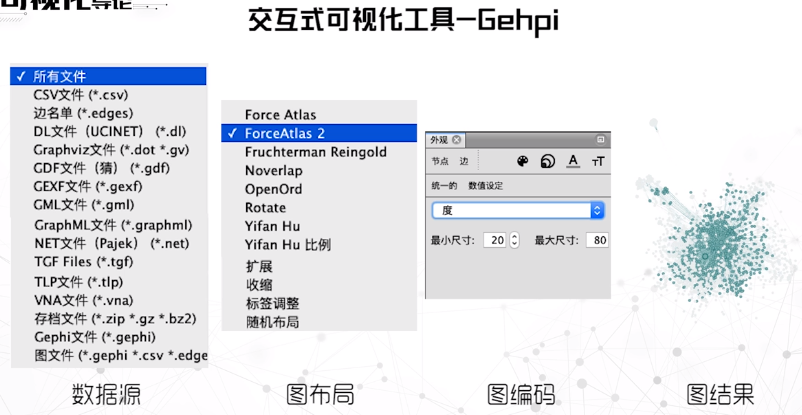
Gehpi
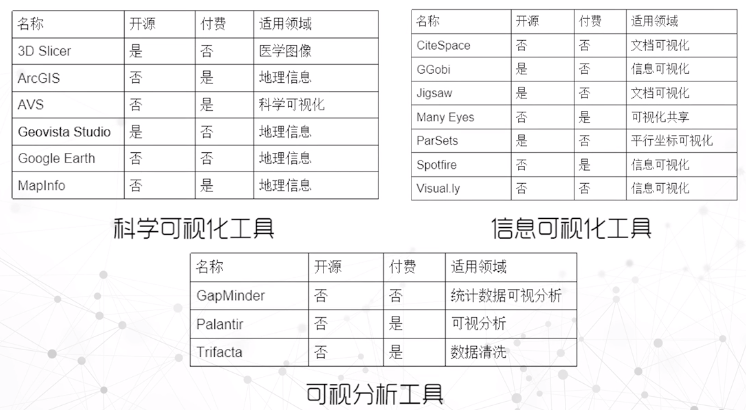
其他
配置式
Vega-Lite

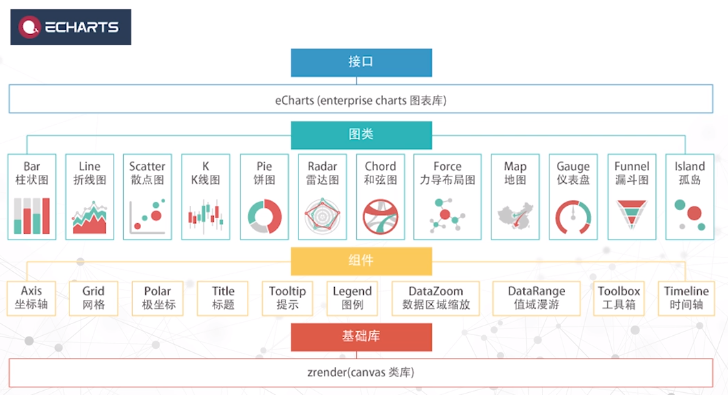
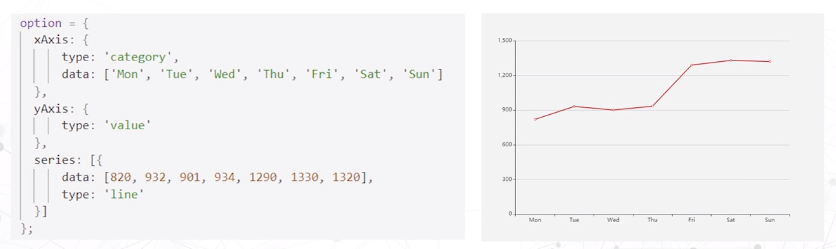
Echarts
其他
- DECK.GL:城市数据和三维可视化
- PLOT.LY:提供了python和R的接口,受众广
- ANTV:G2通用图表,G6图数据和关系型数据,F2针对移动端数据可视化,L7针对地理空间数据可视化
- P4.JS:专门应用于大规模数据的可视化,GPU加速
编程式
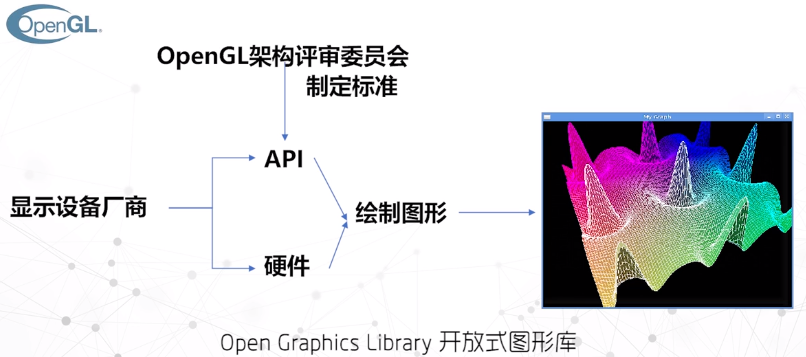
OpenGL
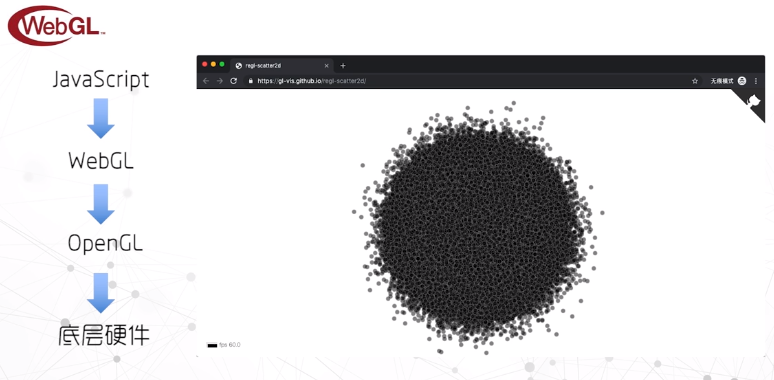
WebGL
Processing
D3.js

其他
- P5.js:适合可视化元素较多的场合
- Visualizaion Toolkit:可以并行处理超大规模的科学数据
- Tulip:基于C++的跨平台的大规模图数据可视化
可视化社区



可视化应用实例

案例分析
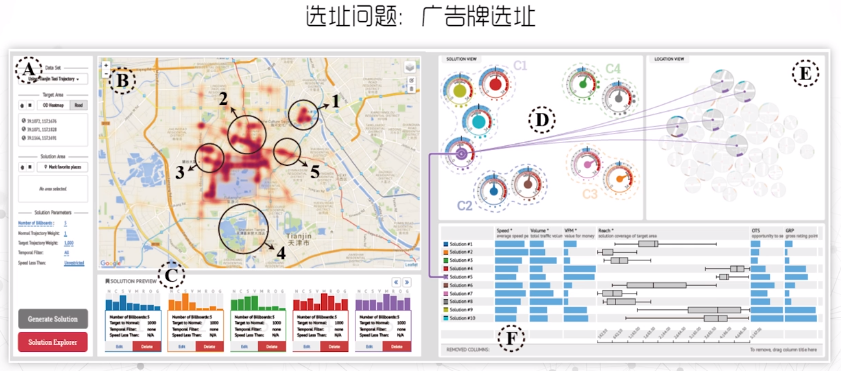
- 城市广告牌选址
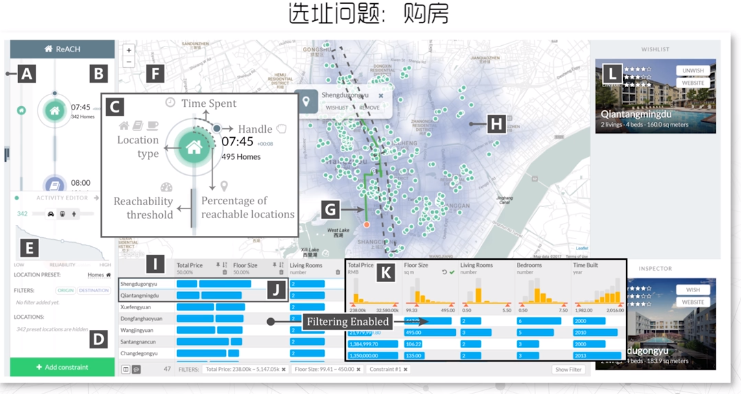
- 购房选择
- 体育数据分析