引子
回归问题是机器学习的一个重要研究方向,而线性回归又是现实中最常用的方法。本次博客的实战部分将使用波士顿房价数据集,进行一元线性回归模型的搭建,并给出模型的预测结果,然后将一元线性回归扩展至多元线性回归,并比较其中差异。理论部分将会对线性回归的原理、优化方法给出公式的推导,对目标函数、评价指标做简单的介绍。
废话不多说,直接开始吧!
实战
首先我们通过sklearn的datasets模块导入波士顿数据集,并将数据集用pandas转换为dataFrame类型,便于后面能对行列数据进行索引操作。
1 | from sklearn import datasets |
前五行数据如下所示:
2
3
4
5
6
0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0 18.7 394.63 2.94 33.4
4 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0 18.7 396.90 5.33 36.2
前13列分别代表的含义为波士顿各地区的:犯罪率,住宅用地比例,非住宅用地比例,边界是否为河流,一氧化氮浓度,住宅平均房间数,自用房屋比例,到各市中心的加权距离,辐射性公路的靠近指数,不动产税率,城镇师生水平,黑人比例,低收入人群比例。最后一列是对应的房价。
这13个因素或多或少都会对该地区的房价产生影响,接下来我们使用matplotlib库来分析各因素对房价的影响,并画出散点图。
1 | import matplotlib.pyplot as plt |
得到的散点图如下:
从上面的散点图中不难看出,RM(住宅平均房间数)和LSTAT(地位低下者比例)对房价的影响是线性的。仔细想想也在情理之中,房间越多,低收入人群比例越低,房价自然越高。
回到主题,我们要用线性回归对房价分析,从数据的分布情况来看,RM和LSTAT显然是最适合线性回归分析的,我们这里选取RM数据进行回归建模。
建模前,我们需要从sklearn的linear_model中导入LinearRegression,在对LinearRegression实例化时有以下常用参数:
fit_intercept : 是否计算该模型的截距,默认为True。如果使用中心化的数据,可以置为False。
normalize : 是否进行标准化,默认为False。建议训练模型之前进行标准化,这里设置False。
训练中常用的属性和方法有:
coef_ : 输入端模型的系数,即权重w
intercept_ : 截距,即偏置b
fit(X, y, sample_weight=None) : 训练用的函数
get_params(deep=True) : 返回对regressor的设置值
score(X, y) : 返回R^2的值
predict(X) : 预测,基于R^2
对这些参数了解之后,就可以开始训练了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 对RM数据(每栋住宅的房间数)进行线性回归分析
from sklearn.linear_model import LinearRegression
import numpy as np
#一元线性回归
rm_X = df_ds['RM'].values.reshape((len(df_ds['RM']), 1))
rm_y = df_ds['price']
# 二元线性回归
# rm_X = df_ds[['RM', 'LSTAT']].values
# rm_y = df_ds['price']
lr = LinearRegression()
lr.fit(rm_X, rm_y)
mse = ((rm_y-lr.predict(rm_X)) ** 2).sum() / len(rm_X)
mae = np.abs(rm_y-lr.predict(rm_X)).sum() / len(rm_X)
print("均方根误差RMSE:{:.2f}".format(mse**0.5))
print("平均绝对误差MAE:{:.2f}".format(mae))
print("确定性系数R^2的值:{:.2f}".format(lr.score(rm_X, rm_y)))
print("线性回归w的值:{}".format(lr.coef_))
print("线性回归b的值:{}".format(lr.intercept_))
输出为:
均方根误差RMSE:6.60
平均绝对误差MAE:4.45
确定性系数R^2的值:0.48
线性回归w的值:[9.10210898]
线性回归b的值:-34.670620776438554
接下来我们就可以根据模型来预测房价了,比如预测拥有5个房间的房子的房价,不到11万美元;而拥有8个房间的房子的房价,大概为38万美元。1
lr.predict([[5], [8]]) # 输出为array([10.83992413, 38.14625107])
为了更好地展示训练效果,画出预测曲线:1
2
3
4
5
6
7
8
9plt.rcParams['font.sans-serif'] = ['SimHei'] #让matplotlib能够显示中文字体
plt.rcParams['axes.unicode_minus'] = False
# 可视化预测曲线
plt.scatter(rm_X, rm_y, color='blue')
plt.plot(rm_X, lr.predict(rm_X), color='green', linewidth=5)
plt.xlabel("$RM$(住宅平均房间数)")
plt.ylabel("$price$")
plt.title("$ralationship\ between\ RM\ and\ price$")
plt.savefig("RM.jpg", dpi=800)
输出为: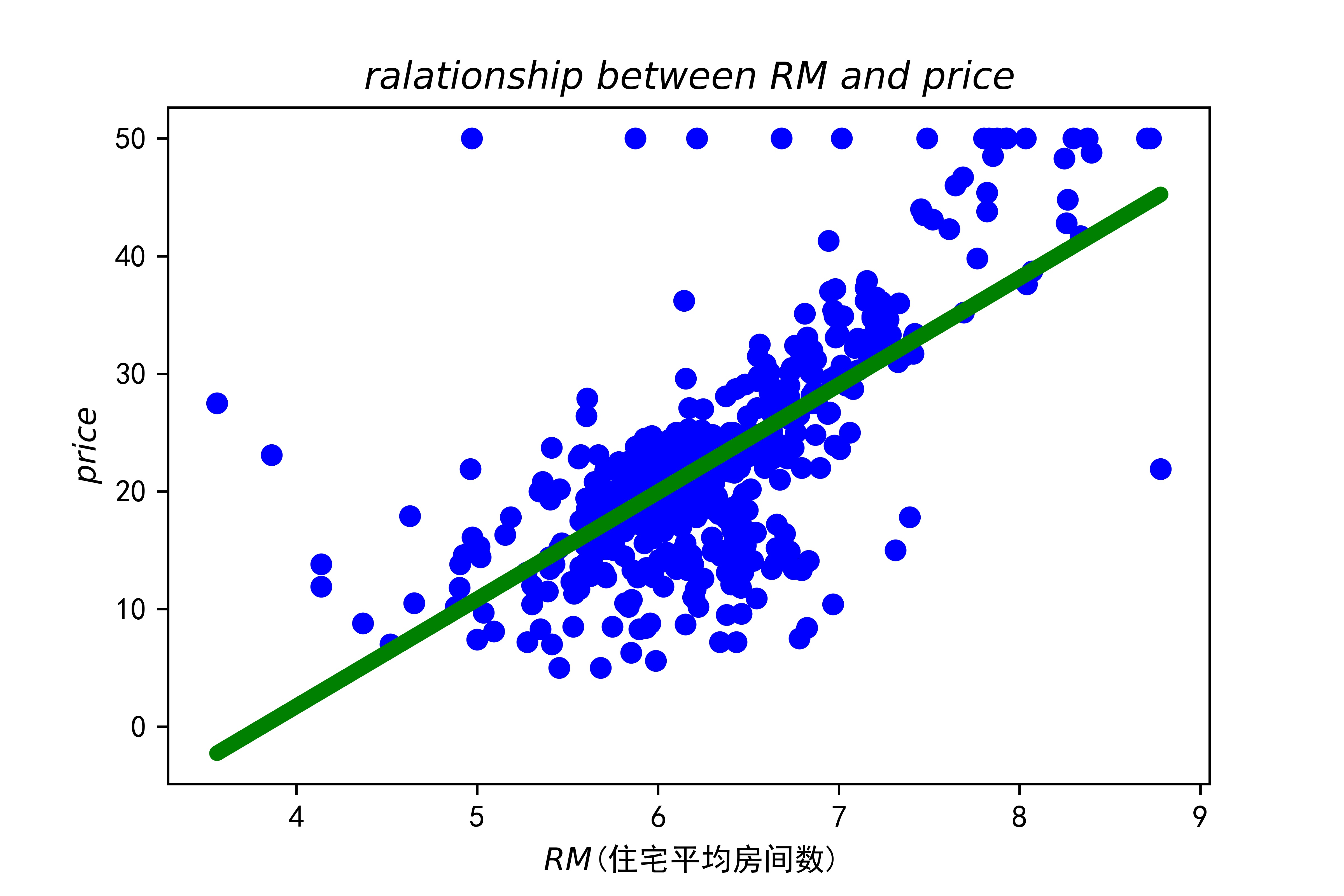
以上建立的模型是一元线性回归,即输入是一维的,只有RM数据。我们可以加上LSTAT数据,建立二元线性回归模型。只需要重新生成输入数据rm_X,其余代码不用修改:1
2
3# 二元线性回归
rm_X = df_ds[['RM', 'LSTAT']].values
rm_y = df_ds['price']
模型的输出结果为:
均方根误差RMSE:5.52
平均绝对误差MAE:3.95
确定性系数R^2的值:0.64
线性回归w的值:[ 5.09478798 -0.64235833]
线性回归b的值:-1.3582728118744818
我们同样预测拥有5个房间和8个房间的房子的房价,并假设低收入人群比例为10%,房价分别为17.7万美元和33万美元1
lr.predict([[5, 10], [8, 10]]) # 输出为array([17.69208377, 32.97644772])
从一元线性回归到二元线性回归,RMSE由6.60降到5.52,MAE由4.45降到3.95,$R^2$由0.48提升到0.64。就这个例子而言,二元线性回归各方面都好于一元线性回归。当然也可以考虑进更多的特征,不再多说。
理论
线性回归的原理
给定数据集$\{(x_1,y_1),(x_2,y_2),…,(x_m,y_m)\}$,$x_i = (x_{i1};x_{i2};x_{i3};…;x_{id}),y_i \in R$ ,其中m表示样本的数量,d表示每个样本的维度。 线性回归试图学得一个通过属性的线性组合来进行预测的函数,即
一般用向量形式写成
我们希望求得$\boldsymbol\omega$和$\boldsymbol b$,使得$f(\boldsymbol X) \rightarrow \boldsymbol y$。显然,关键在于如何衡量$f(\boldsymbol X)$与$\boldsymbol y$之间的差别。
为了方便讨论,我们定义新的$\boldsymbol\omega$为($\boldsymbol\omega;\boldsymbol b$),相应的数据集扩展成一个$m\times (d+1)$大小的矩阵,最后一例元素都为1。这样式1.2可简写为$f(\boldsymbol X)=\boldsymbol\omega^T\boldsymbol X$,所有的参数都被吸收进了$\boldsymbol\omega$向量中。
我们不妨把单个样本的目标值和变量写成如下等式
$\epsilon$表示我们未观测到的随即噪音,根据中心极限定理,不妨假设$\epsilon$是独立同分布,服从高斯分布,即
因此
通过转化,我们引入了参数变量$\boldsymbol\omega$。式子表达的意思是:当$\boldsymbol x=\boldsymbol x^{(i)}$时,在不同参数$\boldsymbol\omega$的作用下,$y=y^{(i)}$发生的概率密度。而我们的目标是让这个概率密度达到最大,来满足$\boldsymbol x=\boldsymbol x^{(i)}$,$y=y^{(i)}$已经发生的事实。模型已定,参数未知,利用已知的样本结果来反推最大概率导致这样结果的参数值,这便是极大似然估计。
我们考虑所有的样本,建立极大似然估计函数,即描述数据遵从当前样本分布的概率分布函数。由于样本的数据集独立同分布,因此可以写成
选择$\boldsymbol\omega$,使得似然函数最大化,这就是极大似然估计的思想。为了方便计算,我们通常对对数似然函数求最大值
显然,只要最小化$\sum^n_{i=1}((\boldsymbol y^{(i)}-\boldsymbol\omega^T\boldsymbol x^{(i)})^2$即可。这一结果除以m就得到了均方误差,因此,用均方误差作为代价函数来优化模型在统计学的角度是合理的。
同时,均方误差有非常好的几何意义,它对应了常用的“欧氏距离”。基于均方误差最小化来进行模型求解的方法称为”最小二乘法”。在线性回归中,最小二乘法就是试图找到一条直线,使所有样本到直线上的欧氏距离之和最小。
线性回归的优化/求解方法
梯度下降法
最小二乘法(矩阵形式)
牛顿法
(未完,待续)