CNN概念
卷积:探测上一层特征的局部连接,即使得原信号特征加强,并降低噪音。
- 卷积核:可以看成是一个权值矩阵窗口,它会在二维输入数据上”滑动”,对当前输入元素做点积运算。
- 特征图:卷积操作后的图像就是特征图。
- 多通道卷积:每个卷积核都是一种特征提取方式,因此可以对每个通道添加一个卷积核以提取该通道的特征。然后将生成的多张特征图相同位置上的值相加,生成一张特征图。最后给这张特征图加一个偏置项产生最终的输出特征图。
- Padding:用额外的”假”像素填充原始边缘,使输出尺寸与输入保持一致
降采样层:在语义上把相似的特征合并起来,即降维(降低网络训练参数及模型的过拟合程度)。
- 池化:计算图像一个区域上的某个特定特征的平均值或最大值。
- 卷积步长大于一:若原始图片尺寸为[N1, N1],卷积核大小为[N2, N2],卷积步长为S,那么卷积之后的大小为$[(N1-N2)/S+1, (N1-N2)/S+1]$
- 事实上,使用卷积步长大于一的降维效果要好于池化。
模型形式
$输入层\rightarrow(卷积层+\rightarrow池化层?)+\rightarrow全连接层+$
实战
导入数据(采用cifar10数据集)
1
2
3
4
5import keras
cifar10 = keras.datasets.cifar10
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
print('训练集:', X_train.shape, y_train.shape) # (50000, 32, 32, 3) (50000, 1)
print('测试集:', X_test.shape, y_test.shape) # (10000, 32, 32, 3) (10000, 1)建立模型,两层卷积,两层池化,提取特征后添加全连接层输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14from keras.models import Sequential
from keras.layers import Conv2D, Dropout, MaxPooling2D, Flatten, Dense
# 搭建网络
model = Sequential([
Conv2D(input_shape=(32, 32, 3), filters=32, kernel_size=(3, 3), activation='relu', padding='same'), # 第1个卷积层:通道 3->32
Dropout(rate=0.3), # 冻结30%神经元,防止过拟合
MaxPooling2D(pool_size=(2, 2)), # 第1个池化层
Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same'),# 第2个卷积层:通道 32->64
Dropout(rate=0.3),
MaxPooling2D(pool_size=(2, 2)), # 第2个池化层
Flatten(), # 平坦层
Dense(128, activation='relu'), # 添加全连接层
Dense(10, activation='softmax') # 添加输出层
])编译模型
1
2
3# 编译网络
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()训练模型
1
2# 训练模型
train_history = model.fit(X_train, y_train, validation_split=0.2, epochs=50, batch_size=32, verbose=2)评估模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def plot_images_labels_prediction(images, labels, preds, index, num=10):
fig = plt.gcf()
fig.set_size_inches(12, 6)
if num>10:
num=10
for i in range(0, num):
ax=plt.subplot(2, 5, i+1)
ax.imshow(images[index])
title = label_dict[labels[index][0]] + '=>' + label_dict[preds[index]]
ax.set_title(title, fontsize=10)
index += 1
plt.show()
fig.savefig('predict.jpg', dpi=800)
# 可视化预测结果
preds = model.predict_classes(X_test)
label_dict = {0:'airplane', 1:'automobile', 2:'bird', 3:'cat', 4:'deer',
5:'dog', 6:'frog', 7:'horse', 8:'ship', 9:'truck'}
plot_images_labels_prediction(X_test, y_test, preds, 0)
# 评估模型
test_loss, test_acc = model.evaluate(X_test, y_test)
print('test_loss:', test_loss) # test_loss: 1.4810904417037964
print('test_acc:', test_acc) # test_acc: 0.6288999915122986
训练流程:
- 选择n个样本组成一个batch,将这个batch丢到神经网络,得到输出结果
- 将输出结果与label丢给loss函数算出本轮的loss。
- 跑BP算法从后往前逐层计算参数之于loss的导数,将每个参数的导数配合步长参数来进行参数更新。
以上就是训练过程的一次迭代。
影响因素
- 网络层数
- 每层神经元个数
- 迭代次数
- 批大小
- 梯度更新方式
- 初始化方式
- 非线性
- 目标函数
- 正规项
调参:
- 数据预处理
- 零均值:将数据的均值变为0,所有数据整体减去均值
- 归一化:将数据各个向量的方差改为1。零均值和归一化就是BN层的思想
- 去相关性:将数据各个分量设置为互相独立的,协方差矩阵是对角阵。
- 白化:协方差矩阵是单位阵,零均值,方差为1
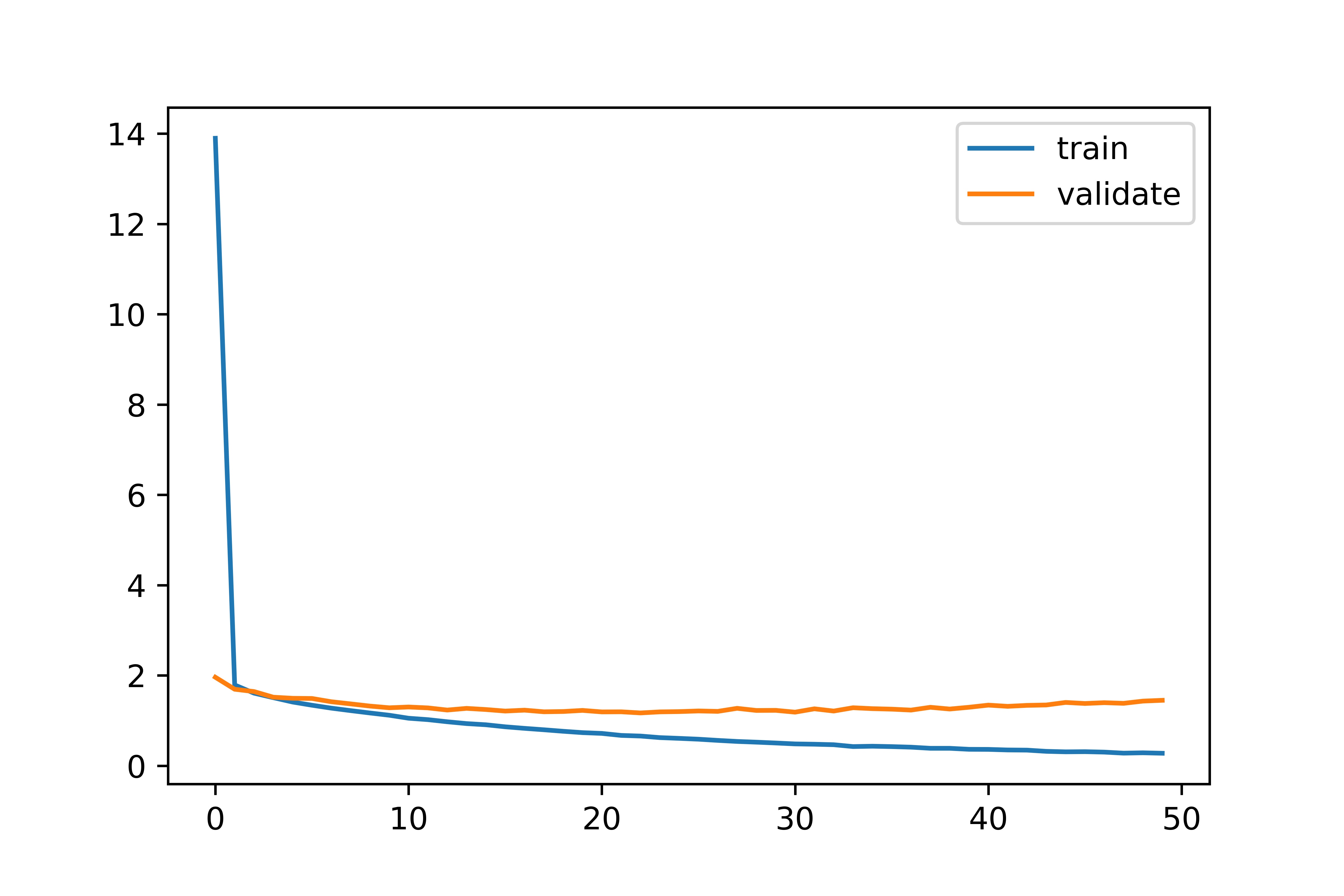
- 看loss函数
- 如果曲线抖动,可能是batch_size过小。可以增大batch_size
- 如果训练集和验证集曲线距离太大,说明过拟合比较严重,可以增大正则项的比重
- 如果训练集和验证集曲线没有距离,说明欠拟合,可以增大网络容量