引子
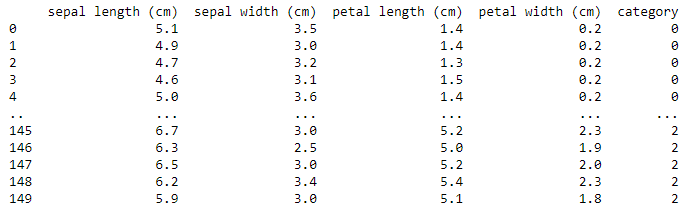
假如现在有一些鸢尾花的特征,也有其对应的标签(如下图所示),如何训练出一个模型,使得任意给一组标签,模型都能给出一个标签预测呢?
这是一个典型的有监督分类的问题,今天我们使用朴素贝叶斯模型来解决这个问题。
假设鸢尾花的特征向量表示为$\boldsymbol x = (x_1, x_2, x_3, x_4)$,可能的分类为$c_i(i取值为0、1、2,即有三个类别)$,利用贝叶斯公式求解在$\boldsymbol x$条件下,分类结果为$c_i$的概率。
这个式子告诉我们,后验概率$P(c_i|\boldsymbol x)$为先验概率$P(c_i)$再乘上一个因子$\frac{P(\boldsymbol x|c_i)}{P(\boldsymbol x)}$,这个因子是否大于1决定了起到的作用是抑制还是促进。这个很好理解,比如没有任何信息的时候,可以判断一个官为贪官的概率为0.5(先验),再知道该官员财产大于一千万后,则判断该官员为贪官的概率为0.8(后验)。
由于这个因子的分母不依赖于类别,当特征值给定时分母可以认为是一个常数,不会影响到最终的分类结果。真正难以计算的是因子的分子类条件概率$P(\boldsymbol x|c_i)$是所有属性上的联合分布。基于有限的训练样本直接计算联合概率,在计算上会遭遇组合爆炸,在数据上会遭遇样本稀疏的问题。这个也好理解,比如假设一个分类器有4个特征,每个特征有10个特征值,则这四个特征的联合概率分布是4维的,可能的情况就有$10^4$种。
为了解决这个问题,”朴素”的条件独立性假设开始发挥作用了:假设每个特征,对于其他特征是独立的。则(1.1)式进一步推导成为
其中$Z$只依赖$\boldsymbol x$,$n$代表特征个数。于是多维的联合概率分布降成了多个单随机变量概率分布的乘积。
相应的分类器则可定义为
其中$c_i$是变量,概率值最大时的$c_i$,即为分类结果。
实战
首先我们使用datasets模块导入鸢尾花数据集,并将字典类型的数据集转化为DataFrame类型,方便进行行列索引操作。
1 | from sklearn.datasets import load_iris |
打印出前五行和后五行
1 | sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) category |
每条记录包含四个特征,分别是:花萼长度,花萼宽度,花瓣长度,花瓣宽度。标签包含3个类别:0代表山鸢尾,1代表变色鸢尾,2代表维吉尼亚鸢尾。我们将利用这四个特征和分类标签来进行贝叶斯分类学习。
在sklearn中,一共有三个朴素贝叶斯的分类算法类,分别是先验为高斯分布的GaussianNB,先验为多项式分布的MultinomialNB和先验为伯努利分布的BernoulliNB。由于鸢尾花样本特征的分布是基本连续的,所以我们使用GaussianNB作为分类算法。这个类的主要参数如下所示
priors:先验概率大小,如果没有给定,模型则根据样本数据自己计算(利用极大似然法)。
var_smoothing:可选参数,所有特征的最大方差
属性有
class_prior_:每个样本的概率
class_count:每个类别的样本数量
classes_:分类器已知的标签类型
theta_:每个类别中每个特征的均值
sigma_:每个类别中每个特征的方差
epsilon_:方差的绝对加值方法
方法和其他模型类似
fit(X,Y):在数据集(X,Y)上拟合模型。
get_params():获取模型参数。
predict(X):对数据集X进行预测。
predict_log_proba(X):对数据集X预测,得到每个类别的概率对数值。predict_proba(X):对数据集X预测,得到每个类别的概率。
score(X,Y):得到模型在数据集(X,Y)的得分情况。
了解了这些参数之后,我们就可以尝试训练了。首先划分数据集前80%为训练集,后20%为测试集。然后实例化GaussianNB,进行训练。1
2
3
4
5
6
7# train_test_split (*arrays,test_size, train_size, rondom_state=None, shuffle=True, stratify=None)
# 建议使用此函数划分数据集,默认是打乱了原始数据的.
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
train_X, test_X, train_y, test_y = train_test_split(df_ds.values[:, :-1], df_ds.values[:, -1], test_size=0.2)
gnb = GaussianNB()
gnb.fit(train_X, train_y)
训练过后,使用测试集来对模型进行检验,计算正确率与得分。1
2
3
4
5
6
7
8
9
10
11import matplotlib.pyplot as plt
%matplotlib inline
y = gnb.predict(test_X)
plt.scatter([i for i in range(len(test_X))], test_y, color="black", marker='v')
plt.scatter([i for i in range(len(test_X))], y, color="red", marker=".")
plt.yticks([0, 1, 2])
plt.xlabel("sample")
plt.ylabel("category")
plt.legend(['actual', 'predict'], bbox_to_anchor=(1, 0.9))
plt.savefig("predict0.2.jpg", dpi=800)
print("准确率:{:.2%}".format(gnb.score(test_X, test_y)))
输出为
准确率:96.67%
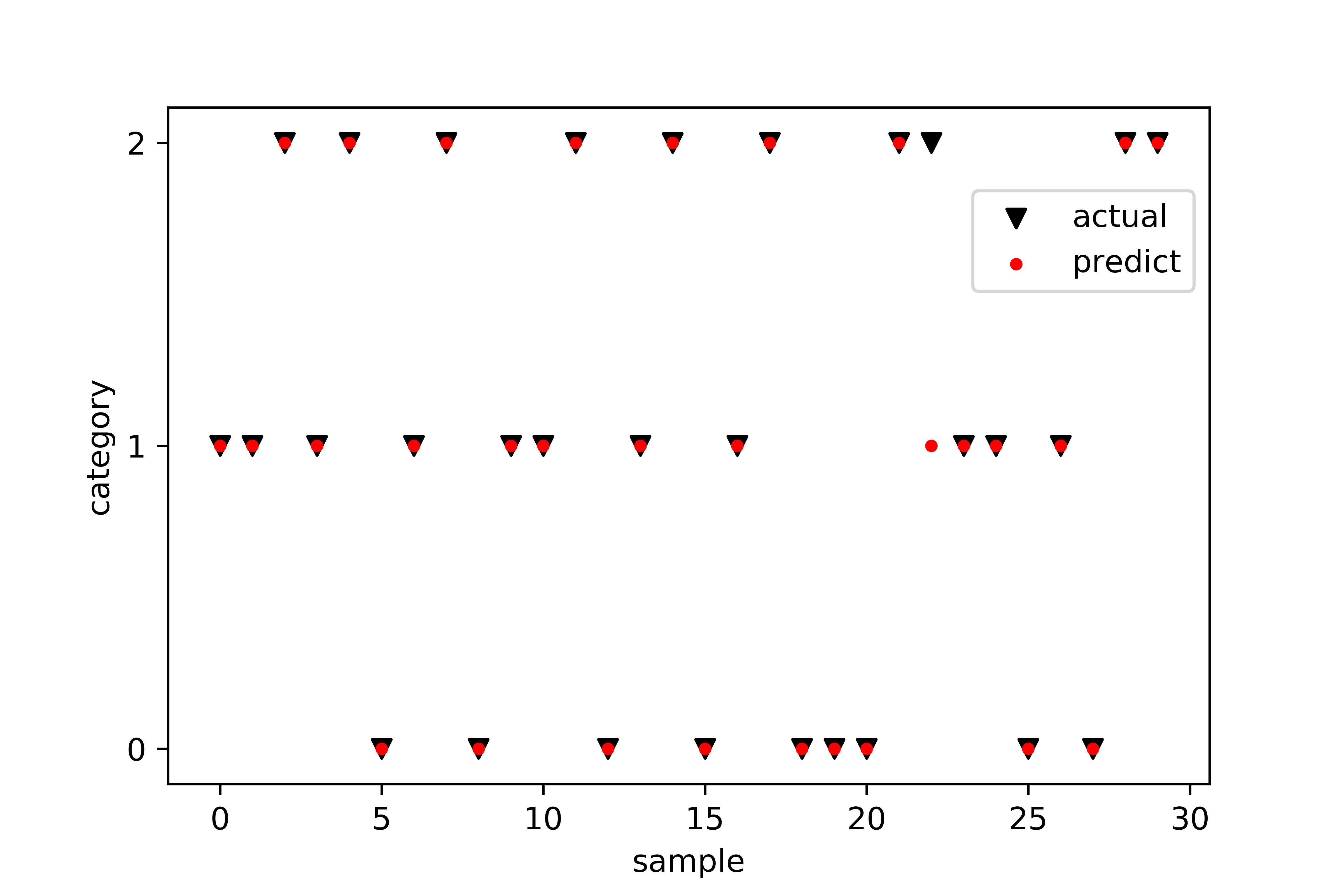
可以看出来朴素贝叶斯的分类能力还是比较强的,准确率达到96%以上,从图中也可以看的出来,30个样本中,只预测错误了一个。
理论
(未完,待续)